
Unlocking the Potential of Active Machine Learning: A Path to Efficient Model Training
26 July 2025
The Power of Active Machine Learning
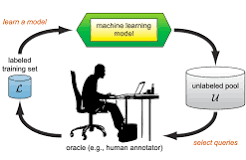
Active machine learning is a dynamic approach that revolutionises the traditional machine learning process by actively selecting which data points to label for training. Unlike passive learning, where all data points are labelled beforehand, active learning involves an iterative process where the model queries the user or a predefined criterion to select the most informative data points for labelling.
This strategy enables machine learning models to achieve higher accuracy with less labelled data, making it a powerful tool in scenarios where labelling data is time-consuming or expensive. By intelligently selecting which data points to label, active learning reduces the need for large labelled datasets while maintaining model performance.
One common active learning strategy is uncertainty sampling, where the model selects data points that it is least confident about for labelling. Another approach is query by committee, where multiple models are trained on different subsets of data, and disagreements among them are used to identify informative instances for labelling.
Active machine learning has applications across various domains, including image classification, natural language processing, and healthcare. In medical imaging, for example, active learning can help radiologists identify rare diseases more efficiently by prioritising challenging cases for annotation.
Overall, active machine learning offers a more efficient and cost-effective way to train machine learning models by focusing on the most relevant data points for labelling. As technology continues to advance, the integration of active learning strategies will play a crucial role in accelerating model development and improving performance across diverse applications.
9 Essential Tips for Effective Active Machine Learning Implementation
- Start with a diverse initial training dataset to cover various scenarios.
- Choose an appropriate active learning strategy based on your data and model.
- Use uncertainty sampling to select the most informative data points for labelling.
- Balance exploration (selecting uncertain samples) and exploitation (leveraging known patterns).
- Regularly retrain your model with newly labelled data to improve performance.
- Consider human annotator expertise and budget constraints when selecting samples.
- Monitor the active learning process to ensure it’s effectively reducing annotation costs.
- Experiment with different query strategies like margin sampling or entropy-based sampling.
- Evaluate the active learning pipeline using metrics like annotation efficiency and model accuracy.
Start with a diverse initial training dataset to cover various scenarios.
When implementing active machine learning, it is crucial to begin with a diverse initial training dataset that covers a wide range of scenarios. By incorporating diverse data points at the outset, the model gains exposure to different patterns and variations, enabling it to better generalise and adapt to new information during the active learning process. A diverse training dataset lays a strong foundation for the model to effectively identify informative instances for labelling, leading to improved performance and robustness across various scenarios.
Choose an appropriate active learning strategy based on your data and model.
When implementing active machine learning, it is crucial to select an active learning strategy that aligns with the specific characteristics of your data and model. By choosing an appropriate strategy tailored to your dataset’s complexity and the model’s learning capabilities, you can maximise the efficiency and effectiveness of the active learning process. Whether utilising uncertainty sampling, query by committee, or another method, matching the strategy to the unique requirements of your data and model is key to optimising performance and achieving accurate results in active machine learning tasks.
Use uncertainty sampling to select the most informative data points for labelling.
Utilising uncertainty sampling in active machine learning is a strategic approach to pinpointing the most valuable data points for labelling. By identifying instances where the machine learning model exhibits the greatest uncertainty, we can effectively target those data points that have the potential to enhance the model’s performance significantly. This method allows us to optimise the labelling process by focusing on areas where the model requires further clarification, ultimately leading to more accurate and efficient learning outcomes.
Balance exploration (selecting uncertain samples) and exploitation (leveraging known patterns).
In active machine learning, finding the right balance between exploration and exploitation is key to maximising the efficiency and effectiveness of the model training process. By actively selecting uncertain samples for labelling (exploration) and leveraging known patterns in the data (exploitation), machine learning models can iteratively improve their performance while minimising the need for extensive labelled datasets. This strategic combination allows models to continuously learn from both familiar and unfamiliar data, ultimately enhancing their accuracy and adaptability across various tasks and domains.
Regularly retrain your model with newly labelled data to improve performance.
Regularly retraining your machine learning model with newly labelled data is a crucial tip to enhance its performance in active machine learning. By incorporating fresh data into the training process, the model can adapt to changing patterns and improve its accuracy over time. This iterative approach ensures that the model remains up-to-date and continues to learn from the most relevant information, ultimately leading to better predictive capabilities and more robust results.
Consider human annotator expertise and budget constraints when selecting samples.
When implementing active machine learning strategies, it is essential to carefully consider the expertise of human annotators and budget constraints when selecting samples for labelling. By taking into account the proficiency of annotators in understanding and accurately labelling data, as well as the financial limitations that may impact the labelling process, organisations can optimise their active learning approach to maximise efficiency and cost-effectiveness. Balancing these factors ensures that the selected samples are not only informative for model training but also aligned with available resources, ultimately leading to more effective machine learning outcomes.
Monitor the active learning process to ensure it’s effectively reducing annotation costs.
Monitoring the active learning process is crucial to ensure that it is effectively reducing annotation costs. By closely observing how the model selects data points for labelling and evaluating the impact on overall annotation expenses, organisations can fine-tune their active learning strategies for optimal cost-efficiency. Regular monitoring allows for adjustments to be made in real-time, ensuring that resources are allocated efficiently and maximising the benefits of active machine learning in minimising annotation costs.
Experiment with different query strategies like margin sampling or entropy-based sampling.
To enhance the effectiveness of active machine learning, it is beneficial to experiment with various query strategies such as margin sampling or entropy-based sampling. These different approaches offer unique ways to select the most informative data points for labelling, ultimately improving the model’s performance and efficiency. By exploring a range of query strategies, researchers and practitioners can fine-tune their active learning process and achieve more accurate results with less labelled data.
Evaluate the active learning pipeline using metrics like annotation efficiency and model accuracy.
When implementing active machine learning, it is essential to evaluate the effectiveness of the active learning pipeline using key metrics such as annotation efficiency and model accuracy. By assessing annotation efficiency, which measures how effectively the model selects data points for labelling, and model accuracy, which indicates the performance of the trained model, you can gain valuable insights into the efficacy of your active learning strategy. Monitoring these metrics allows you to fine-tune the active learning process, improve data labelling efficiency, and enhance the overall performance of your machine learning models.