
Unveiling the Power of Deep Learning: An Illustrative Example
19 November 2023
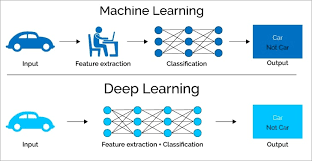
Deep learning is an artificial intelligence (AI) technique that has been gaining in popularity in recent years. It is a form of machine learning that uses large amounts of data and complex algorithms to identify patterns and make predictions. Deep learning is particularly useful for tasks such as image recognition, natural language processing, and autonomous driving.
In this article, we will discuss a deep learning example and explain how it works. The example we will use is a convolutional neural network (CNN) used to classify images of dogs and cats. This type of network is commonly used for image classification tasks because it can learn the features of an image without being explicitly programmed to do so.
To create the CNN, we first need to define the input data. In this case, we will use images of cats and dogs. We then need to create a set of layers in the network that will process the input data. The first layer is called the convolutional layer, which applies a filter to the input image to detect features such as edges or shapes. The second layer is called the pooling layer, which reduces the size of the input data by combining similar features together. Finally, we have a fully connected layer which takes all of these features and creates a prediction about what type of animal is in the image.
Once our CNN is trained on our input data, it can be used to classify new images with high accuracy. For example, if we feed an image into our trained CNN, it can accurately predict whether it contains a cat or dog with high accuracy based on its learned features from training.
Deep learning has become increasingly popular due to its ability to automate complex tasks such as image classification without requiring explicit programming instructions from humans. By using large datasets and powerful algorithms such as convolutional neural networks, deep learning can produce results with higher accuracy than traditional machine learning approaches. This makes deep learning an invaluable tool for many applications in AI today.
7 Essential Tips for Deep Learning Success
- Familiarise yourself with the different types of deep learning algorithms and their applications.
- Learn about the different neural network architectures such as convolutional neural networks (CNNs), recurrent neural networks (RNNs) and long short-term memory (LSTM).
- Start by using existing open-source deep learning frameworks such as TensorFlow, Keras or PyTorch to build your project.
- Experiment with different datasets to find the most suitable one for your project.
- Utilise GPU computing to speed up training times where possible.
- Monitor model performance during training and adjust hyperparameters accordingly to improve accuracy and reduce overfitting if necessary.
- Make sure you are familiar with best practices in machine learning such as data preprocessing, feature engineering and regularisation techniques which can help improve model performance significantly
Familiarise yourself with the different types of deep learning algorithms and their applications.
When diving into the world of deep learning, it is essential to familiarise yourself with the different types of algorithms and their applications. Deep learning offers a wide range of algorithms, each designed for specific tasks and data types.
One common type of deep learning algorithm is the convolutional neural network (CNN). CNNs are particularly effective in image and video analysis tasks, such as object recognition and facial recognition. By using layers of convolutional filters, CNNs can extract meaningful features from images, enabling accurate classification.
Another popular algorithm is the recurrent neural network (RNN), which excels in sequential data analysis. RNNs are often used for natural language processing tasks like speech recognition, machine translation, and text generation. Their ability to retain memory from previous inputs makes them suitable for tasks that involve temporal dependencies.
Generative adversarial networks (GANs) are yet another fascinating type of deep learning algorithm. GANs consist of two neural networks: a generator and a discriminator. The generator generates synthetic data samples while the discriminator tries to distinguish between real and fake samples. GANs have found applications in image synthesis, such as generating realistic images from scratch or transforming images from one domain to another.
Understanding the strengths and weaknesses of these different algorithms is crucial for choosing the right approach for your specific task. By familiarising yourself with their applications, you can leverage deep learning’s power effectively.
Moreover, keep in mind that deep learning is a rapidly evolving field with new algorithms constantly being developed. Staying updated with the latest research papers and advancements will help you explore cutting-edge techniques and push the boundaries of what’s possible with deep learning.
So, take the time to delve into each algorithm’s characteristics, study their applications in various domains, and experiment with different architectures. This knowledge will empower you to make informed decisions when designing your own deep learning models or applying existing ones to solve complex problems.
Remember that understanding the different types of deep learning algorithms and their applications is the first step towards harnessing the full potential of this exciting field. So, embrace the learning journey and unlock the transformative power of deep learning in your projects.
Learn about the different neural network architectures such as convolutional neural networks (CNNs), recurrent neural networks (RNNs) and long short-term memory (LSTM).
When diving into the world of deep learning, it is essential to understand the different neural network architectures that form the backbone of this field. Three popular architectures to familiarize yourself with are convolutional neural networks (CNNs), recurrent neural networks (RNNs), and long short-term memory (LSTM) networks.
Convolutional neural networks (CNNs) are widely used for image and video processing tasks. They excel at recognizing patterns and extracting features from visual data. CNNs consist of convolutional layers that apply filters to input images, followed by pooling layers that downsample the data. This architecture enables CNNs to learn hierarchical representations of images and achieve impressive accuracy in tasks such as object recognition and image classification.
Recurrent neural networks (RNNs) are designed for sequential data processing, making them suitable for tasks involving time series analysis, natural language processing, and speech recognition. Unlike traditional feedforward neural networks, RNNs have feedback connections that allow information to flow in loops. This loop-like structure enables RNNs to retain information from previous steps, making them effective at capturing temporal dependencies in data.
Long short-term memory (LSTM) networks are a specialized type of RNN architecture that addresses the vanishing gradient problem associated with traditional RNNs. LSTMs have additional components called “gates” that control the flow of information within the network. These gates help LSTMs selectively remember or forget information over long sequences, making them particularly useful for tasks requiring memory retention over extended periods.
By familiarizing yourself with these different neural network architectures – CNNs for image-related tasks, RNNs for sequential data analysis, and LSTMs for long-term dependencies – you can leverage their strengths when approaching various deep learning problems.
Understanding these architectures will not only broaden your knowledge but also empower you to choose the appropriate model for specific applications. As you delve deeper into deep learning, keep exploring these architectures and stay updated with the latest advancements in neural networks.
Start by using existing open-source deep learning frameworks such as TensorFlow, Keras or PyTorch to build your project.
Deep learning is a powerful tool in the modern world of technology, and it can be used to create amazing projects. However, it can be difficult to get started with deep learning if you don’t have any prior experience. Fortunately, there are a number of existing open-source deep learning frameworks that can be used to help you get started quickly and easily.
TensorFlow, Keras and PyTorch are three of the most popular open-source deep learning frameworks currently available. They are all designed to make it easier for developers to build projects using deep learning technology. Each framework has its own strengths and weaknesses, so it’s important to research each one before deciding which one is best for your project.
TensorFlow is one of the most popular open-source deep learning frameworks available. It has a wide range of features that make it suitable for many different types of projects. It also has an extensive library of pre-trained models that can be used as a starting point for your project.
Keras is another popular open-source deep learning framework that is easy to use and understand. It also has a large library of pre-trained models that can help speed up development time.
PyTorch is an excellent choice for those who want to build projects using the latest advancements in deep learning technology. It has a wide range of features and capabilities, making it suitable for many different types of projects.
No matter which framework you choose, starting by using existing open-source deep learning frameworks such as TensorFlow, Keras or PyTorch will give you a strong foundation on which to build your project quickly and easily.
Experiment with different datasets to find the most suitable one for your project.
When it comes to deep learning, one of the key factors that can greatly impact the success of your project is the choice of dataset. Experimenting with different datasets is a valuable tip that can help you find the most suitable one for your specific deep learning project.
Every deep learning task requires a dataset that is relevant and representative of the problem you are trying to solve. For example, if you are working on an image classification project, using a dataset that contains a wide variety of images with different angles, lighting conditions, and backgrounds would be ideal. This will allow your model to learn robust features and generalize well to unseen data.
By experimenting with different datasets, you can evaluate their quality and suitability for your project. It’s important to consider factors such as dataset size, diversity, and relevance to your specific problem domain. Sometimes, a larger dataset may not always be better if it lacks diversity or does not cover all possible scenarios.
Another aspect to consider is the availability of pre-processed datasets versus creating your own. While pre-processed datasets are convenient and widely used, they may not always align perfectly with your project requirements. Creating your own dataset allows you to have more control over its composition and ensure it meets your specific needs.
Furthermore, experimenting with different datasets can also help in identifying any potential biases or limitations within them. Bias in datasets can lead to biased models that produce unfair or inaccurate results. By testing different datasets, you can identify any biases or limitations early on and take steps to mitigate them.
In conclusion, experimenting with different datasets is an essential step in any deep learning project. It allows you to find the most suitable dataset that aligns with your problem domain and ensures accurate results. Remember to consider factors like dataset size, diversity, relevance, and potential biases while making your selection. With the right dataset in hand, you’ll be on track towards building powerful and effective deep learning models.
Utilise GPU computing to speed up training times where possible.
Deep learning is a powerful tool for many applications, such as image recognition, natural language processing and more. However, it can take a long time to train the models that are used in deep learning algorithms. One way to speed up training times is to utilise GPU computing.
GPUs are specialised pieces of hardware designed for rapid calculations and are particularly suited to deep learning tasks. By using GPUs instead of CPUs for deep learning tasks, training times can be significantly reduced. This can be especially beneficial when dealing with large datasets or complex models.
In addition to speeding up training times, using GPUs can also help reduce the cost of running deep learning algorithms. By reducing the amount of time required for training, fewer resources need to be allocated and costs can be kept down.
Utilising GPU computing for deep learning tasks is an effective way of improving performance and reducing costs. It is important to remember however that this approach may not be suitable for all applications and should only be used when necessary.
Monitor model performance during training and adjust hyperparameters accordingly to improve accuracy and reduce overfitting if necessary.
Deep learning is an increasingly popular and powerful tool for machine learning. It has been used to solve a variety of complex problems, from image recognition to natural language processing. However, it is important to monitor the performance of a deep learning model during training, and adjust the hyperparameters accordingly, in order to improve accuracy and reduce overfitting.
Hyperparameters are parameters that are set before training begins. They can have a significant impact on the performance of a deep learning model. For example, they can determine the number of layers in the neural network, or the learning rate used during training. By adjusting these hyperparameters, it is possible to fine-tune the model for better accuracy and reduce overfitting.
Monitoring model performance during training is key to achieving optimal results with deep learning. By tracking metrics such as accuracy and loss, it is possible to identify when changes in hyperparameters are needed in order to improve performance. For example, if accuracy is not increasing as expected or if loss values are unusually high, then adjusting the hyperparameters might be necessary.
In summary, monitoring model performance during training and adjusting hyperparameters accordingly can help improve accuracy and reduce overfitting when using deep learning models. This simple tip can go a long way towards achieving better results with deep learning models.
Make sure you are familiar with best practices in machine learning such as data preprocessing, feature engineering and regularisation techniques which can help improve model performance significantly
When delving into the world of deep learning, it is crucial to be familiar with best practices in machine learning. These practices, such as data preprocessing, feature engineering, and regularisation techniques, play a vital role in improving the performance of your models.
Data preprocessing involves preparing and cleaning your data before feeding it into the deep learning model. This step ensures that the data is in a suitable format and free from any inconsistencies or errors. Common techniques used in data preprocessing include handling missing values, scaling features, and encoding categorical variables. By performing these steps effectively, you can enhance the quality of your input data and subsequently improve the accuracy of your deep learning model.
Feature engineering is another essential practice in machine learning that can greatly impact model performance. It involves selecting or creating relevant features from the available dataset to improve the predictive power of your model. This process requires domain knowledge and creativity to identify informative features that can contribute to better predictions. Feature engineering techniques may include dimensionality reduction, creating interaction terms, or transforming variables to better represent relationships within the data.
Regularisation techniques are employed to prevent overfitting, a common issue in machine learning where a model performs well on training data but fails to generalize to unseen data. Regularisation methods such as L1 and L2 regularization help control the complexity of a deep learning model by adding penalties to its parameters during training. These penalties discourage overly complex models and encourage simpler ones that generalize better.
By incorporating these best practices into your deep learning workflow, you can significantly enhance the performance and reliability of your models. Understanding how to preprocess data effectively, engineer relevant features, and apply regularisation techniques will empower you to build more accurate and robust deep learning models.
Remember that mastering these best practices requires practice and continuous learning. Stay updated with advancements in machine learning research and explore new techniques as they emerge. With dedication and an understanding of these best practices, you’ll be well-equipped to tackle complex deep learning tasks and achieve optimal results.