
Unlocking the Power of ML Data: Revolutionizing Decision-Making and Business Operations
25 November 2023
Ml Data: Unlocking the Potential of Machine Learning
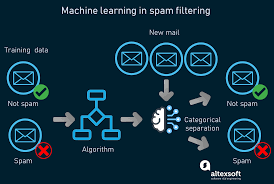
The world of technology is constantly evolving, and with it, so too is the way in which data is collected and analysed. Machine learning (ML) data is one of the most powerful tools available to organisations looking to improve their business processes, from customer service to predictive analytics. ML data is a type of big data which uses algorithms to analyse large datasets and identify patterns and trends. This type of data can be used to make predictions about future events, as well as gain insights into customer behaviour and preferences.
The potential applications for ML data are vast, ranging from healthcare to finance. For example, in healthcare, ML data can be used to identify high-risk patients or predict how diseases will progress over time. In finance, ML data can be used to detect fraudulent activity or identify new investment opportunities. With such a wide range of potential applications, it’s no wonder that many organisations are turning to ML data for help in making more informed decisions.
One of the key benefits of using ML data is its ability to automate processes and reduce human error. By leveraging machine learning algorithms, organisations can quickly process large amounts of data and accurately identify patterns and trends without needing manual input from humans. This automation not only saves time but also helps reduce costs associated with manual labour. Additionally, because machine learning algorithms use historical datasets for training purposes, they are able to learn from past events and make more accurate predictions about future outcomes than humans could alone.
However, there are some challenges associated with using ML data that organisations should be aware of before investing in this technology. Firstly, it’s important for organisations to ensure that they have access to high-quality datasets in order for machine learning algorithms to work effectively. Secondly, it’s important that organisations have the necessary expertise on hand in order to interpret the results correctly – if not done correctly then inaccurate conclusions may be drawn which could lead to costly mistakes being made further down the line. Finally, there is also a risk that machine learning algorithms may become biased if they are trained on flawed datasets – this means that it’s important for organisations to ensure that their datasets are free from bias before using them for training purposes.
Overall, ML data has huge potential when it comes to helping organisations streamline their processes and make better decisions based on accurate insights into customer behaviour or market trends. However, there are some challenges associated with using this technology which need careful consideration before investing in it – ensuring access to high-quality datasets and having appropriate expertise on hand being two key considerations here. With these considerations taken into account however there’s no doubt that ML data has huge potential when it comes improving business operations across a wide range of sectors
9 Essential Tips for ML Data Collection and Analysis in English (UK)
- Always start with a clear goal in mind when collecting and analysing data.
- Ensure that the data you collect is relevant to your project and meets the objectives of your research.
- Use reliable sources for data collection, such as official government websites or industry-specific resources.
- Clean up any inaccurate or incomplete data before beginning analysis, as this can lead to incorrect results and conclusions.
- Utilise visualisation tools such as charts, graphs and maps to better understand patterns in the data you have collected.
- Make use of machine learning algorithms to identify trends or correlations within datasets quickly and accurately without manual intervention.
- Don’t forget to consider ethical issues when collecting or using personal data from individuals – always ensure that they are aware of how their information is being used and stored securely by you or third parties involved in the project..
- Keep track of all changes made during analysis so that it is easy to go back if needed for further investigation or comparison with other datasets in future projects..
- Stay up-to-date with current trends in ML technology by attending conferences, seminars, reading articles etc., so that you can apply best practices when working on ML projects
Always start with a clear goal in mind when collecting and analysing data.
Always Start with a Clear Goal in Mind When Collecting and Analysing ML Data
In the world of machine learning, data is the lifeblood that fuels accurate predictions and valuable insights. However, it’s crucial to approach data collection and analysis with a clear goal in mind. Having a well-defined objective not only helps streamline the process but also ensures that the data collected is relevant and useful.
Starting with a clear goal enables you to focus your efforts on gathering the right type of data. It helps you identify what specific information you need to achieve your desired outcome. Without a clear goal, you may end up collecting excessive or irrelevant data, which can be time-consuming and resource-intensive to process.
When setting a goal for ML data collection and analysis, it’s important to consider what problem or question you are trying to solve. Are you looking to improve customer satisfaction? Enhance product recommendations? Reduce operational costs? By clearly defining your objective, you can tailor your data collection efforts accordingly.
Moreover, having a clear goal helps guide your analysis process. It allows you to structure the analysis around specific metrics or variables that are most relevant to your objective. This focused approach ensures that the insights derived from the ML data align with your intended purpose.
Additionally, starting with a clear goal in mind provides clarity for decision-making. When faced with multiple options or paths during the analysis phase, referring back to your original objective can help guide you towards making informed choices. It keeps you grounded and ensures that every step taken aligns with your ultimate goal.
Lastly, having a clear goal enhances communication and collaboration within teams working on ML projects. When everyone understands the purpose behind the data collection and analysis efforts, it fosters alignment and enables better coordination towards achieving common objectives.
In conclusion, starting with a clear goal in mind when collecting and analysing ML data is essential for success. It streamlines the process, ensures relevance of collected data, guides analysis, aids decision-making, and promotes effective teamwork. So, before diving into the world of ML data, take the time to define your goal – it will be the compass that leads you towards valuable insights and impactful outcomes.
Ensure that the data you collect is relevant to your project and meets the objectives of your research.
Ensuring Relevant and Objective-driven ML Data for Successful Projects
When embarking on a machine learning (ML) project, one of the critical factors for success lies in the data you collect. The quality and relevance of your data can significantly impact the accuracy and effectiveness of your ML models. Therefore, it is crucial to ensure that the data you collect aligns with the objectives of your research.
Collecting relevant data means gathering information that directly relates to the problem you are trying to solve or the insights you aim to gain. Irrelevant or unnecessary data can not only hinder progress but also introduce noise and bias into your models, leading to inaccurate predictions or insights.
To ensure that your collected ML data is relevant, start by clearly defining your project’s objectives. Understand what questions you want to answer or problems you want to solve using machine learning techniques. With a clear objective in mind, you can then identify the specific types of data needed to achieve those goals.
Consider both the quantity and quality of your data. While having a large dataset can be advantageous, it is equally important to focus on collecting high-quality data that accurately represents the real-world scenarios relevant to your project. Ensure that your dataset encompasses a diverse range of samples and covers various scenarios or conditions that may impact your ML models’ performance.
Additionally, consider the ethical aspects associated with collecting and using data. Ensure compliance with privacy regulations and obtain consent when necessary. Respecting individuals’ privacy rights builds trust while ensuring responsible use of personal information.
Regularly evaluate and validate the collected ML data against your project’s objectives throughout its lifecycle. This practice helps identify any gaps or biases in the dataset early on, allowing you to make necessary adjustments or modifications as required.
By prioritizing relevance and aligning collected ML data with research objectives, you set yourself up for success in developing accurate models and gaining meaningful insights from your machine learning projects. Remember: quality over quantity matters when it comes to ML data, and a well-defined and objective-driven approach will yield the best results.
Use reliable sources for data collection, such as official government websites or industry-specific resources.
Using Reliable Sources for ML Data: Ensuring Accuracy and Trustworthiness
When it comes to collecting data for machine learning (ML) purposes, the quality and reliability of the sources you use play a crucial role in the accuracy and effectiveness of your models. To ensure the best possible outcomes, it is essential to rely on trustworthy sources that provide accurate and up-to-date information. This article highlights the importance of using reliable sources for ML data collection, such as official government websites or industry-specific resources.
Official government websites are often considered as highly reliable sources of data. Governments typically invest significant resources in collecting and maintaining accurate information about various aspects of society, such as demographics, economic indicators, or public health statistics. By accessing data from these official sources, you can be confident that you are working with validated and authoritative information.
Industry-specific resources are another valuable option for obtaining reliable ML data. Many industries have dedicated organizations or associations that compile and publish industry-specific data sets. These resources often provide detailed insights into market trends, consumer behavior, or technological advancements within a particular sector. Leveraging such data can be immensely beneficial when training ML models tailored to specific industries.
By using reliable sources for ML data collection, you can enhance the accuracy of your models and make more informed decisions based on trustworthy insights. Here are a few key advantages:
- Accuracy: Reliable sources ensure that the data you collect is accurate, free from errors or biases that could potentially impact your analysis.
- Currency: Official government websites and industry-specific resources often update their datasets regularly, providing access to the most recent information available in your field of interest.
- Credibility: Using reputable sources enhances the credibility of your research or analysis, making it more likely to be trusted by stakeholders or decision-makers who rely on your findings.
- Compliance: In certain industries where regulatory compliance is crucial (e.g., healthcare or finance), relying on official sources helps ensure adherence to legal requirements and industry standards.
When embarking on ML projects, it is important to invest time and effort in identifying reliable sources for data collection. While the internet offers a vast amount of information, not all sources are equally reliable or accurate. By prioritizing official government websites and industry-specific resources, you can significantly improve the quality and reliability of your ML data.
Remember, using reliable sources is just one aspect of effective ML data collection. It is equally important to ensure that the data you collect aligns with your specific research objectives and that appropriate preprocessing techniques are applied to clean and prepare the data for analysis. With a solid foundation of reliable data, you can unlock the full potential of machine learning and make well-informed decisions that drive success in your chosen field.
Clean up any inaccurate or incomplete data before beginning analysis, as this can lead to incorrect results and conclusions.
Cleaning Up ML Data: The Key to Accurate Results
When it comes to analysing machine learning (ML) data, accuracy is paramount. ML algorithms rely heavily on the quality of the data they are trained on, and any inaccuracies or incompleteness in the dataset can significantly impact the results and conclusions drawn from the analysis. Therefore, it is crucial to clean up any inaccurate or incomplete data before diving into the analysis phase.
Inaccurate or incomplete data can arise from various sources, such as human error during data entry, system glitches, or even external factors affecting data collection. Regardless of the source, failing to address these issues upfront can lead to misleading outcomes and erroneous conclusions.
Cleaning up ML data involves a series of steps aimed at identifying and rectifying inaccuracies or missing values. This process typically includes tasks such as removing duplicate entries, correcting inconsistent formatting, filling in missing values using appropriate techniques (e.g., imputation), and validating data against predefined rules or constraints.
By investing time and effort into cleaning up ML data before analysis, organisations can ensure that their models are built on a solid foundation. Here are a few reasons why this step is crucial:
- Enhanced Model Performance: ML algorithms thrive on accurate and complete data. By cleaning up the dataset, you eliminate noise and inconsistencies that may hinder your model’s ability to learn patterns effectively. This leads to more reliable predictions and better overall performance.
- Reliable Insights: Inaccurate or incomplete data can skew your analysis results and lead to incorrect insights. By ensuring data cleanliness, you increase the trustworthiness of your findings and enable more informed decision-making based on accurate information.
- Avoiding Costly Mistakes: Relying on flawed or incomplete data can have severe consequences for businesses. Incorrect conclusions drawn from unreliable ML analyses may lead to misguided strategies, wasted resources, or missed opportunities. Cleaning up your ML data mitigates these risks by providing a solid basis for decision-making.
Remember, cleaning up ML data is not a one-time task. As data evolves and new information becomes available, it’s essential to continuously monitor and update your datasets to maintain their accuracy and completeness.
In conclusion, cleaning up inaccurate or incomplete ML data is an essential step in ensuring reliable and accurate results. By investing time and effort into this crucial process, organisations can unlock the full potential of their ML analyses, make informed decisions, and stay ahead in today’s data-driven world.
Utilise visualisation tools such as charts, graphs and maps to better understand patterns in the data you have collected.
Utilise Visualisation Tools to Uncover Patterns in ML Data
In the world of machine learning, data is the key to unlocking valuable insights and making informed decisions. However, raw data alone can often be overwhelming and difficult to comprehend. This is where visualisation tools come into play, enabling us to better understand the patterns hidden within the data we have collected.
Visualisation tools such as charts, graphs, and maps provide a visual representation of complex datasets, making it easier for us to identify trends, correlations, and anomalies. By presenting data in a visual format, these tools allow us to grasp patterns that might otherwise go unnoticed.
Charts are particularly useful when it comes to displaying numerical data. Line charts can show how variables change over time, while bar charts provide a clear comparison between different categories. Scatter plots help us visualize relationships between two variables and identify any underlying patterns or clusters.
Graphs take visualisation a step further by representing connections or relationships between various elements in the data. Network graphs can reveal intricate connections within large datasets, while tree maps provide a hierarchical view of different categories and their proportions.
Maps are invaluable when dealing with geospatial data. They allow us to plot data points on a map based on their geographical coordinates. This enables us to uncover spatial patterns or regional variations that may exist within our dataset.
By utilising these visualisation tools effectively, we can gain deeper insights into our ML data. We can identify outliers that deviate from expected patterns or detect trends that may influence future predictions. Visualisations also aid in communicating findings to stakeholders who may not have technical expertise but still need to understand the implications of the data.
Moreover, visualisations facilitate storytelling with data by making it more engaging and accessible. They help convey complex information in a simple and intuitive manner, allowing for better decision-making across various domains such as business analytics, healthcare research, or environmental studies.
In conclusion, harnessing the power of visualisation tools is crucial for understanding the patterns and trends hidden within ML data. By representing complex information in a visually appealing manner, charts, graphs, and maps enable us to uncover valuable insights that can drive innovation and improve decision-making processes. So, let’s embrace these tools and unlock the full potential of our ML data.
Make use of machine learning algorithms to identify trends or correlations within datasets quickly and accurately without manual intervention.
Harnessing the Power of Machine Learning Algorithms for Data Analysis
In today’s data-driven world, organisations are constantly seeking ways to extract valuable insights from their vast datasets. One powerful tool that can assist in this process is machine learning (ML) algorithms. These algorithms have the ability to quickly and accurately identify trends or correlations within datasets, all without the need for manual intervention.
Traditionally, analysing large datasets required significant time and effort from data analysts. However, with ML algorithms, this process can be automated, saving valuable time and resources. By leveraging these algorithms, organisations can uncover hidden patterns or relationships within their data that may not be immediately apparent to human analysts.
ML algorithms are designed to learn from historical data and make predictions or classifications based on patterns they discover. This ability allows them to sift through vast amounts of information in a fraction of the time it would take a human analyst. By utilising ML algorithms, organisations can rapidly identify trends or correlations that may have otherwise gone unnoticed.
The benefits of using ML algorithms for data analysis are numerous. Firstly, it enables organisations to make more informed decisions based on accurate insights derived from their datasets. Whether it’s understanding customer preferences, predicting market trends, or identifying potential risks, ML algorithms can provide valuable information that drives business success.
Secondly, by automating the analysis process with ML algorithms, organisations can reduce the risk of human error. These algorithms follow predefined rules and patterns when analysing data, eliminating subjective biases that may arise from manual analysis. This ensures more consistent and reliable results.
Lastly, ML algorithms allow for scalability and adaptability as datasets continue to grow in size and complexity. As technology advances and more data becomes available, these algorithms can handle larger volumes of information without sacrificing accuracy or efficiency. This scalability makes them ideal for businesses looking to stay ahead in an increasingly data-centric landscape.
In conclusion, harnessing the power of machine learning algorithms for data analysis offers numerous advantages. By leveraging these algorithms, organisations can quickly and accurately identify trends or correlations within their datasets, without the need for manual intervention. This enables informed decision-making, reduces the risk of human error, and ensures scalability as data volumes increase. Embracing ML algorithms is a valuable step towards unlocking the full potential of data and gaining a competitive edge in today’s data-driven world.
Don’t forget to consider ethical issues when collecting or using personal data from individuals – always ensure that they are aware of how their information is being used and stored securely by you or third parties involved in the project..
Safeguarding Personal Data in Machine Learning: Ethical Considerations
In the age of data-driven decision making, machine learning has emerged as a powerful tool for extracting valuable insights. However, it is crucial to remember that behind every data point lies personal information about individuals. As organisations harness the potential of machine learning data, it is imperative to address ethical concerns and ensure the protection of personal data.
When collecting or using personal data from individuals, it is vital to prioritize transparency and consent. Individuals should be fully aware of how their information will be used and stored securely. This means being transparent about the purpose of data collection, the entities involved in the project, and any potential risks or implications.
Obtaining informed consent is not only an ethical responsibility but also a legal requirement in many jurisdictions. It ensures that individuals have willingly agreed to share their personal information for specific purposes. Consent should be sought explicitly and in a clear manner, leaving no room for ambiguity.
Furthermore, organisations must take measures to ensure the security and confidentiality of personal data throughout its lifecycle. This includes implementing robust cybersecurity protocols, encryption techniques, access controls, and regular audits to prevent unauthorized access or breaches.
It is also essential to consider the potential impact on individuals when making decisions based on machine learning algorithms. Biases can inadvertently seep into models if training datasets are not diverse or representative enough. Organisations should strive for fairness and inclusivity by regularly evaluating and addressing biases that may arise.
Lastly, accountability plays a crucial role in ethical data handling practices. Organisations must take responsibility for their actions and be prepared to address any concerns or complaints raised by individuals whose data they have collected. Establishing clear channels for communication and providing avenues for redress can help build trust with users.
In summary, while machine learning offers immense opportunities for innovation, it is essential to approach it ethically when dealing with personal data. Transparency, informed consent, security measures, fairness, and accountability should be at the forefront of every data-driven project. By doing so, organisations can not only harness the power of machine learning but also foster trust and respect for individuals’ privacy rights.
Keep track of all changes made during analysis so that it is easy to go back if needed for further investigation or comparison with other datasets in future projects..
The Importance of Tracking Changes in ML Data Analysis
When it comes to working with machine learning (ML) data, keeping track of all changes made during the analysis process is crucial. This practice ensures that you have a clear record of the steps taken and allows for easy reference if further investigation or comparison with other datasets is required in future projects.
ML data analysis involves various stages, including data preprocessing, feature engineering, model selection, and evaluation. Throughout these stages, it’s common to experiment with different techniques, parameters, and approaches to find the most effective solution. However, without tracking these changes, it can become challenging to replicate or understand the reasoning behind certain outcomes.
By documenting every change made during analysis, you create a comprehensive log that serves multiple purposes. Firstly, it enables reproducibility. If you need to revisit a particular project or share your work with others, having a detailed record ensures that others can follow your steps and achieve consistent results. This is especially important in collaborative environments where multiple team members may be working on the same project.
Secondly, tracking changes facilitates further investigation. Sometimes during analysis, unexpected results or anomalies may arise. By referring back to your log of changes, you can easily identify where adjustments were made and investigate potential causes or correlations. This helps in troubleshooting issues and refining your models for better performance.
Furthermore, keeping track of changes allows for effective comparison between different datasets or projects. It provides a valuable reference point when analyzing similar datasets or when trying out new techniques on existing data. By having a documented history of previous analyses and their outcomes, you can make informed decisions about which methods are more suitable for specific scenarios.
To implement this practice effectively, consider using version control systems like Git or utilizing specialized tools designed for ML experimentation management. These tools allow you to create branches or checkpoints within your analysis workflow so that you can easily navigate between different versions and compare results.
In conclusion, tracking changes made during ML data analysis is essential for reproducibility, further investigation, and effective comparison. By maintaining a comprehensive log of all modifications, you ensure that your work is transparent, adaptable, and can be easily referenced in future projects. Embracing this practice will enhance the reliability and efficiency of your ML data analysis endeavors.
Stay up-to-date with current trends in ML technology by attending conferences, seminars, reading articles etc., so that you can apply best practices when working on ML projects
Staying Ahead in ML Data: Embrace Continuous Learning
In the rapidly evolving field of machine learning (ML), it is crucial for professionals to stay up-to-date with the latest trends and advancements. By actively seeking opportunities to learn, such as attending conferences, seminars, and reading articles, you can ensure that you are equipped with the knowledge and best practices needed to excel in your ML projects.
Conferences and seminars provide an excellent platform for networking with industry experts and gaining insights into cutting-edge research and developments. These events often feature keynote speeches, panel discussions, and workshops that cover a wide range of ML topics. By participating in these events, you can broaden your understanding of ML technology, learn about emerging techniques, and gain inspiration from real-world use cases.
Additionally, reading articles from reputable sources is a great way to stay informed about the latest trends in ML. There are numerous online platforms dedicated to publishing articles on ML advancements, research papers, case studies, and industry news. By regularly exploring these resources, you can deepen your understanding of new algorithms, frameworks, tools, and methodologies that can enhance your ML projects.
Continuous learning not only helps you stay abreast of current trends but also allows you to apply best practices when working on ML projects. As the field evolves rapidly, what may have been considered a best practice yesterday might no longer be relevant today. By staying updated on the latest techniques and approaches used by experts in the field through attending conferences or reading articles, you can ensure that your work aligns with industry standards.
Moreover, being knowledgeable about current trends in ML technology gives you a competitive edge. It allows you to propose innovative solutions to business challenges and implement state-of-the-art algorithms that produce accurate results. Clients and employers value professionals who demonstrate expertise in the latest ML practices as it showcases their commitment to delivering high-quality work.
In conclusion, staying up-to-date with current trends in ML technology is essential for professionals in the field. By actively engaging in continuous learning through attending conferences, seminars, and reading articles, you can acquire valuable knowledge and apply best practices to your ML projects. Embrace the opportunity to learn, grow, and contribute to the exciting world of machine learning.