
Unravelling the Wonders of Neural Networks and Deep Learning
10 March 2024
Unveiling the Mysteries of Neural Networks and Deep Learning
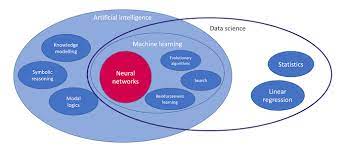
The realms of artificial intelligence (AI) and machine learning have been revolutionised by the advent of neural networks and deep learning. These two interconnected technologies have become the backbone of many modern AI systems, powering everything from voice recognition services to self-driving cars. This article aims to demystify these concepts and explore their significance in today’s technological landscape.
What Are Neural Networks?
Neural networks are a series of algorithms modelled after the human brain, designed to recognise patterns and interpret sensory data through a kind of machine perception, labelling, or clustering. The fundamental building blocks of neural networks are neurons, or nodes, which are interconnected in layers to form a network.
There are three main types of layers within a typical neural network:
- Input Layer: This is where the network receives its input data.
- Hidden Layers: These layers perform computations through weighted connections and are considered the “brain” of the network.
- Output Layer: The final layer that produces the outcome or prediction.
The connections between these neurons carry an associated weight that adjusts as learning occurs within the network. Through a process called training, neural networks learn by adjusting these weights based on the error rate of outcomes when compared to expected results.
The Emergence of Deep Learning
Deep learning is essentially an advanced subset of machine learning that utilises multi-layered neural networks – hence why we often refer to them as deep neural networks. What sets deep learning apart is its ability to learn at multiple levels of abstraction, allowing it to recognise patterns in unstructured data such as images, sound, and text.
The depth in deep learning refers to the number of layers through which data is transformed. More layers allow for more complex features to be extracted at each level, from simple edges in images at lower layers to highly complex features at deeper layers.
The Power Behind Deep Learning: Algorithms and Hardware
To train deep neural networks effectively requires significant computational power and large datasets. Algorithms such as backpropagation provide a means for adjusting internal parameters that decide how input data is processed in hidden layers for an output decision.
In addition to sophisticated algorithms, advancements in hardware have also propelled deep learning forward. Graphical processing units (GPUs) are particularly effective at handling parallel tasks and have become crucial for training large-scale neural networks efficiently.
The Impact on Society
The impact that neural networks and deep learning have had on society cannot be overstated:
- In healthcare, they assist with predictive diagnostics and personalised medicine approaches.
- In finance, they enable more accurate fraud detection systems and algorithmic trading strategies.
- In automotive industries, they’re key components behind autonomous vehicle technology.
- In consumer electronics, they’ve improved user experience with speech recognition and recommendation systems.
This is just scratching the surface; their potential applications span countless other fields as well.
Challenges Ahead
Despite their promise, there remain challenges with neural networks and deep learning such as overfitting (where models perform well on training data but poorly on new data), ethical considerations around biased datasets leading to biased models, transparency in decision-making processes (the ‘black box’ problem), and environmental concerns due to high energy consumption during training phases.
Moving Forward with Responsible Innovation
To harness the full potential while mitigating risks associated with neural networks and deep learning requires responsible innovation. This involves developing ethical guidelines for AI development, creating more energy-efficient computing methods, improving model interpretability, ensuring diversity within training datasets – all while fostering public understanding about these technologies’ capabilities and limitations.
“Deep Learning vs Machine Learning: Understanding the Distinctions”
“Training Protocols for Neural Networks in the Deep Learning Process”
4. “Practical Uses
- What are neural networks and how do they work?
- What is the difference between deep learning and machine learning?
- How are neural networks trained in deep learning?
- What are the applications of neural networks and deep learning in real-world scenarios?
- What are the challenges faced when implementing neural networks and deep learning models?
- How do convolutional neural networks (CNNs) differ from other types of neural networks?
- Can you explain the concept of backpropagation in the context of deep learning?
- What role do activation functions play in neural networks and deep learning models?
- How can one get started with building and training their own neural network models?
What are neural networks and how do they work?
Neural networks are advanced algorithms inspired by the human brain’s structure and function. They consist of interconnected nodes, or neurons, organised in layers to process and interpret complex data. These networks learn through a training process where the connections between neurons are adjusted based on the error rate of predicted outcomes. By passing data through multiple layers of computation, neural networks can extract intricate patterns and make intelligent decisions. In essence, neural networks work by mimicking the brain’s ability to recognise patterns and learn from experience, enabling them to perform tasks such as image recognition, natural language processing, and more with remarkable accuracy and efficiency.
What is the difference between deep learning and machine learning?
A commonly asked question in the realm of artificial intelligence is: “What is the difference between deep learning and machine learning?” Machine learning is a broader concept that encompasses various techniques where algorithms are trained to learn patterns from data and make decisions or predictions without being explicitly programmed. On the other hand, deep learning is a subset of machine learning that utilises multi-layered neural networks to process complex data and extract high-level features for more accurate predictions. In essence, while machine learning focuses on algorithms that improve automatically through experience, deep learning specifically refers to neural networks with multiple layers that enable advanced pattern recognition and abstraction.
How are neural networks trained in deep learning?
Training neural networks in deep learning involves a process known as backpropagation, which is a key algorithm for adjusting the weights of connections between neurons to minimise the difference between predicted outputs and actual targets. During training, input data is fed forward through the network, producing an output that is compared to the desired target. The error between the predicted output and the target is then calculated and propagated backward through the network to adjust the weights incrementally using gradient descent. This iterative process continues until the network’s predictions align closely with the actual targets, enabling it to learn and improve its performance over time.
What are the applications of neural networks and deep learning in real-world scenarios?
The applications of neural networks and deep learning in real-world scenarios are vast and impactful. From healthcare to finance, automotive to consumer electronics, these technologies have revolutionised industries by enabling predictive diagnostics, personalised medicine, fraud detection systems, autonomous vehicles, speech recognition, recommendation systems, and much more. Their ability to extract complex patterns from unstructured data has transformed how we approach problem-solving and decision-making in various fields. As neural networks and deep learning continue to advance, their applications will only expand further, shaping the future of technology and society.
What are the challenges faced when implementing neural networks and deep learning models?
Implementing neural networks and deep learning models presents several challenges that practitioners must navigate. One primary concern is the requirement for vast amounts of data to train these models effectively; without sufficient quality data, the model’s ability to generalise and make accurate predictions can be significantly compromised. Additionally, these models demand extensive computational resources and processing power, often necessitating sophisticated hardware such as GPUs or TPUs, which can be cost-prohibitive. Another hurdle is the potential for overfitting, where a model learns the training data too well but fails to perform accurately on unseen data. Moreover, there are concerns around the interpretability of these models – often referred to as the ‘black box’ problem – which can make it difficult to understand how decisions are made or to identify potential biases in the model’s outputs. Finally, ethical considerations must be addressed, ensuring that AI systems are designed and deployed in a manner that avoids reinforcing existing societal biases or inequalities. Addressing these challenges is crucial for the successful and responsible application of neural networks and deep learning in real-world scenarios.
How do convolutional neural networks (CNNs) differ from other types of neural networks?
Convolutional neural networks (CNNs) distinguish themselves from other types of neural networks through their specialised architecture tailored for processing grid-like data, such as images. Unlike traditional neural networks, CNNs leverage convolutional layers that apply filters to extract features from input data spatially, enabling them to capture patterns efficiently. This design allows CNNs to learn hierarchical representations of features at different levels, making them particularly effective in tasks like image recognition and computer vision. By utilising shared weights and pooling layers, CNNs can reduce the number of parameters needed for training, enhancing their ability to generalise well on new data.
Can you explain the concept of backpropagation in the context of deep learning?
In the context of deep learning, backpropagation is a fundamental concept that plays a crucial role in training neural networks. Backpropagation refers to the process by which the network adjusts its internal parameters, or weights, by propagating the error backwards from the output layer to the input layer. This iterative process involves calculating the gradient of the loss function with respect to each weight in the network, allowing for incremental updates that minimise the difference between predicted and actual outputs. Through backpropagation, neural networks learn to make more accurate predictions and improve their performance over time by fine-tuning their internal representations of data patterns.
What role do activation functions play in neural networks and deep learning models?
Activation functions are a crucial component in neural networks and deep learning models, serving as the nonlinear transformation that introduces complexity and flexibility into the network’s decision-making process. These functions determine whether a neuron should be activated or not based on the input it receives, allowing the network to learn complex patterns and make more accurate predictions. By introducing nonlinearity, activation functions enable neural networks to approximate any continuous function, enhancing their ability to model intricate relationships within data and improve overall performance in various tasks such as image recognition, natural language processing, and more.
How can one get started with building and training their own neural network models?
Embarking on the journey of building and training your own neural network models can be both exhilarating and challenging. To begin, it’s essential to have a foundational understanding of programming, preferably in languages such as Python, which is widely used in the AI community due to its simplicity and rich ecosystem of data science libraries. Start by familiarising yourself with machine learning frameworks like TensorFlow or PyTorch, which offer tools to create and train neural networks. Online courses, tutorials, and MOOCs can provide structured learning paths; meanwhile, engaging with community forums and open-source projects can offer practical experience. Initially, experimenting with simple models using well-documented datasets such as MNIST for handwritten digit recognition is a great way to understand the process. As you gain confidence, progressively tackle more complex projects by increasing the number of layers (depth) or experimenting with different architectures like convolutional or recurrent neural networks. Remember that building neural networks is an iterative process that involves tuning parameters, managing data sets, and continuously learning from new developments in the field.