
Exploring the Synergy of Computer Vision and Deep Learning: A Visionary Approach
04 November 2024
The Power of Computer Vision and Deep Learning
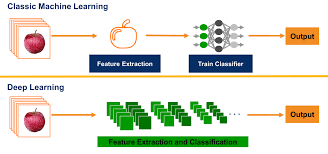
Computer vision, a field of artificial intelligence, has revolutionised the way machines perceive and interpret visual information. By combining computer vision with deep learning, a subset of machine learning, we have unlocked incredible capabilities that were once thought to be only in the realm of science fiction.
Computer vision algorithms enable machines to understand images and videos, allowing them to “see” and analyse visual data much like humans do. Deep learning, on the other hand, involves training neural networks with vast amounts of data to recognise patterns and make decisions based on that data.
When computer vision is combined with deep learning, the results are truly remarkable. From self-driving cars that can navigate complex roadways to facial recognition systems that enhance security measures, the applications of this technology are endless.
One of the key advantages of using deep learning in computer vision is its ability to automatically learn features from raw data. This means that machines can adapt and improve their performance over time without human intervention.
Furthermore, the accuracy and efficiency of computer vision systems have been greatly enhanced by the advancements in deep learning algorithms. Tasks that were once considered too challenging for machines, such as object detection and image classification, can now be performed with high precision.
As we continue to push the boundaries of computer vision and deep learning, we are unlocking new possibilities in various industries. From healthcare to agriculture to retail, businesses are leveraging this technology to gain insights from visual data like never before.
In conclusion, computer vision coupled with deep learning is transforming the way we interact with technology and opening up a world of opportunities for innovation. As these technologies continue to evolve, we can expect even more groundbreaking applications that will shape our future in ways we have yet to imagine.
Top 5 Essential Tips for Enhancing Computer Vision with Deep Learning
- Ensure you have a large and diverse dataset for training your computer vision models.
- Pre-process your data effectively to improve the performance of your deep learning models.
- Experiment with different architectures such as CNNs and RNNs to find the best model for your specific task.
- Regularly fine-tune your model on new data to keep it up-to-date and accurate.
- Consider using pre-trained models or transfer learning to speed up development and improve performance.
Ensure you have a large and diverse dataset for training your computer vision models.
Ensuring that you have a large and diverse dataset for training your computer vision models is crucial for achieving accurate and robust results. A comprehensive dataset allows the deep learning algorithms to learn from a wide range of visual inputs, helping the model to generalise well and perform effectively across different scenarios. By exposing the model to varied data, you can improve its ability to recognise patterns and make informed decisions, ultimately enhancing the overall performance of your computer vision system.
Pre-process your data effectively to improve the performance of your deep learning models.
Effective data pre-processing is a crucial step in enhancing the performance of deep learning models in computer vision. By carefully preparing and cleaning the data before feeding it into the model, you can improve accuracy, reduce training time, and ensure better generalisation. Techniques such as normalisation, data augmentation, and feature scaling can help to remove noise, standardise input values, and increase the model’s ability to learn meaningful patterns from the data. Investing time and effort into pre-processing your data can significantly impact the overall success of your deep learning projects.
Experiment with different architectures such as CNNs and RNNs to find the best model for your specific task.
To maximise the potential of computer vision and deep learning, it is advisable to experiment with various architectures, such as Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs), in order to identify the most effective model for your specific task. By exploring different architectures and fine-tuning them according to the requirements of the task at hand, you can optimise performance and achieve more accurate results in image recognition, object detection, or any other visual data processing task.
Regularly fine-tune your model on new data to keep it up-to-date and accurate.
To ensure the continued accuracy and relevance of your computer vision and deep learning model, it is essential to regularly fine-tune it with new data. By incorporating fresh data into the training process, you enable the model to adapt to changing patterns and trends, ultimately enhancing its performance and maintaining its accuracy over time. This proactive approach not only ensures that your model stays up-to-date with the latest information but also allows it to evolve and improve its capabilities as new data becomes available.
Consider using pre-trained models or transfer learning to speed up development and improve performance.
When delving into the realm of computer vision and deep learning, it is advisable to consider utilising pre-trained models or transfer learning techniques to expedite development processes and enhance performance outcomes. By leveraging existing models that have been trained on vast datasets, developers can benefit from the knowledge and features learned by these models, thereby reducing the need to start from scratch. Transfer learning allows for the adaptation of pre-trained models to new tasks or datasets, enabling quicker development cycles and improved accuracy in applications requiring visual data analysis. This approach not only accelerates progress but also facilitates the creation of more efficient and effective computer vision systems.