
Unlocking the Power of Keras in Machine Learning
18 September 2024
Keras Machine Learning: Simplifying Deep Learning for Everyone
In the ever-evolving world of artificial intelligence and machine learning, Keras has emerged as a powerful and user-friendly library that enables developers to build and experiment with deep learning models quickly and efficiently. Whether you are a seasoned data scientist or a beginner in the field, Keras offers an accessible approach to harnessing the capabilities of neural networks.
What is Keras?
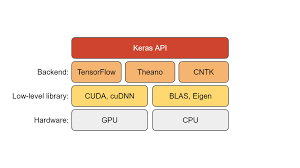
Keras is an open-source neural network library written in Python. It was developed with a focus on enabling fast experimentation by providing a high-level interface for building and training deep learning models. Initially released in 2015 by François Chollet, Keras has since become one of the most popular libraries in the machine learning community.
Why Choose Keras?
There are several reasons why Keras has gained widespread adoption:
- User-Friendly API: Keras offers a simple and intuitive API that allows users to build complex neural networks with just a few lines of code.
- Modularity: The library is designed with modularity in mind, making it easy to create custom layers, loss functions, and optimisers.
- Compatibility: Keras can run on top of several backends, including TensorFlow, Microsoft Cognitive Toolkit (CNTK), and Theano. This flexibility ensures that users can leverage different computational resources as needed.
- Extensive Documentation: Comprehensive documentation and numerous tutorials are available to help users get started quickly and effectively.
Core Concepts in Keras
Keras simplifies many aspects of building deep learning models. Here are some core concepts:
Layers
A neural network is composed of layers, which are the basic building blocks in Keras. Layers receive input data, process it through weights (parameters), and pass the transformed data to subsequent layers. Common types of layers include dense (fully connected) layers, convolutional layers for image processing, recurrent layers for sequence data, and more.
Models
Keras provides two main types of models: the Sequential model and the Functional API. The Sequential model is suitable for simple stack-based architectures where each layer has exactly one input tensor and one output tensor. The Functional API allows for more complex architectures with shared layers or multiple inputs/outputs.
Compilation
The compilation step involves specifying the optimiser (e.g., SGD, Adam), loss function (e.g., mean squared error, categorical cross-entropy), and metrics (e.g., accuracy) used to evaluate model performance during training.
Training
The training process involves feeding data into the model through methods such as .fit(), which iteratively adjusts weights based on loss gradients calculated from predictions versus actual outcomes.
A Simple Example Using Keras
The following example demonstrates how to build a simple neural network using Keras:
<script src="https://gist.github.com/anonymous/1234567890abcdef1234567890abcdef.js"></script><script>
from keras.models import Sequential
from keras.layers import Dense
# Create a sequential model
model = Sequential()
# Add input layer with 32 units
model.add(Dense(32, activation='relu', input_shape=(784,)))
# Add hidden layer with 64 units
model.add(Dense(64, activation='relu'))
# Add output layer with 10 units
model.add(Dense(10, activation='softmax'))
# Compile the model
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# Summary of the model architecture
model.summary()
</script>
</code>
</pre>
This example creates a simple feedforward neural network for classification tasks such as digit recognition from images (e.g., MNIST dataset). The network consists of an input layer with 32 units followed by two hidden layers with 64 units each before outputting probabilities across 10 classes using softmax activation.
The Future of Machine Learning with Keras
Keras continues evolving alongside advancements in AI research while maintaining its commitment towards accessibility ease-of-use among practitioners at all levels expertise within this dynamic field development . As more organisations individuals embrace power potential offered by deep learning technologies , tools like will undoubtedly play pivotal role shaping future innovation progress across industries worldwide .
Top 5 Tips for Effective Machine Learning with Keras
- Use the Sequential model for simple linear stack of layers.
- Choose appropriate activation functions based on the problem (e.g. ReLU for hidden layers, sigmoid for binary classification).
- Compile your model with the correct loss function and optimizer for your task.
- Split your data into training and testing sets to evaluate model performance.
- Regularize your model using techniques like dropout or L2 regularization to prevent overfitting.
Use the Sequential model for simple linear stack of layers.
When working with Keras machine learning, it is advisable to utilise the Sequential model for constructing a straightforward linear stack of layers. The Sequential model is well-suited for scenarios where each layer has precisely one input tensor and one output tensor, making it ideal for creating simple architectures without complex interconnections. By leveraging the Sequential model in Keras, developers can easily build and train neural networks in a sequential manner, streamlining the process of implementing basic deep learning models efficiently and effectively.
Choose appropriate activation functions based on the problem (e.g. ReLU for hidden layers, sigmoid for binary classification).
When working with Keras machine learning models, it is crucial to select the right activation functions tailored to the specific problem at hand. For instance, using Rectified Linear Unit (ReLU) activation functions in hidden layers can help the model learn complex patterns effectively by allowing non-linearity and preventing vanishing gradient issues. On the other hand, employing the sigmoid activation function is ideal for binary classification tasks as it squashes the output between 0 and 1, providing a clear decision boundary. By choosing appropriate activation functions based on the nature of the problem, developers can enhance model performance and achieve more accurate results in their machine learning endeavours.
Compile your model with the correct loss function and optimizer for your task.
When working with Keras machine learning models, it is crucial to compile your model with the appropriate loss function and optimizer tailored to your specific task. The choice of loss function determines how well the model is performing during training by measuring the disparity between predicted and actual values. Likewise, selecting the right optimizer influences how efficiently the model adjusts its weights to minimise this disparity. By carefully considering and configuring these components during compilation, you can enhance the model's performance and enable it to effectively learn and adapt to the intricacies of your data.
Split your data into training and testing sets to evaluate model performance.
When working with Keras machine learning models, it is crucial to split your data into training and testing sets. This practice allows you to evaluate the performance of your model accurately. By training the model on a subset of the data and then testing it on a separate unseen portion, you can assess how well your model generalises to new data. Splitting the data helps prevent overfitting and provides valuable insights into the model's ability to make predictions on unseen data. This simple yet essential tip can significantly impact the reliability and effectiveness of your Keras machine learning models.
Regularize your model using techniques like dropout or L2 regularization to prevent overfitting.
To enhance the performance and generalisation of your Keras machine learning model, it is crucial to incorporate regularisation techniques such as dropout or L2 regularization. Overfitting, a common issue in deep learning models, occurs when the model performs exceptionally well on training data but fails to generalise effectively to unseen data. By implementing dropout, which randomly deactivates a portion of neurons during training, or L2 regularization, which adds a penalty term to the loss function based on the magnitude of weights, you can effectively prevent overfitting and improve the robustness of your model. These techniques promote better generalisation and help achieve more reliable and accurate predictions in real-world scenarios.