
Unlocking the Potential of Multimodal Deep Learning: A Comprehensive Exploration
23 August 2024
Multimodal Deep Learning: A Comprehensive Overview
By [Author’s Name]
Introduction
In the rapidly evolving field of artificial intelligence, multimodal deep learning has emerged as a powerful approach to integrating and understanding data from multiple sources. By leveraging various types of data such as text, images, audio, and video, multimodal deep learning models can achieve more comprehensive and accurate insights compared to traditional single-modality models.
What is Multimodal Deep Learning?
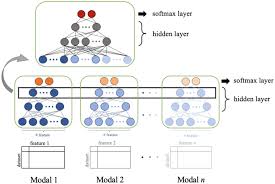
Multimodal deep learning refers to the use of deep neural networks to process and analyse data from multiple modalities simultaneously. Each modality provides unique information that can complement and enhance the understanding derived from other modalities. For example, combining visual and textual data can significantly improve the performance of tasks such as image captioning or sentiment analysis.
Applications of Multimodal Deep Learning
Image Captioning
Image captioning involves generating descriptive text for a given image. By combining visual features extracted from images with linguistic features derived from text, multimodal deep learning models can produce more accurate and contextually relevant captions.
Sentiment Analysis
Sentiment analysis aims to determine the emotional tone behind a series of words or phrases. By integrating textual data with audio signals (such as speech intonation) or facial expressions in videos, multimodal models can achieve a deeper understanding of the sentiment being expressed.
Autonomous Vehicles
In autonomous vehicles, sensors like cameras, LiDARs, and radars provide different types of information about the environment. Multimodal deep learning enables these vehicles to fuse data from various sensors for better perception and decision-making capabilities.
Healthcare Diagnostics
The healthcare sector benefits immensely from multimodal deep learning by integrating medical imaging (e.g., X-rays), electronic health records (EHRs), and genomic data for more accurate diagnostics and personalised treatment plans.
Challenges in Multimodal Deep Learning
Top 5 Frequently Asked Questions About Multimodal Deep Learning
- What does multimodal mean in machine learning?
- What is multimodal in machine learning?
- What is multimodal approach in deep learning?
- What are multimodal deep learning challenges?
- What is an example of a multimodal data?
What does multimodal mean in machine learning?
In the context of machine learning, the term “multimodal” refers to the integration and processing of data from multiple distinct sources or modalities. These modalities can include various forms of data such as text, images, audio, video, and sensor readings. By combining these diverse types of information, multimodal machine learning models can achieve a more holistic understanding and improved performance on complex tasks compared to models that rely on a single type of data. This approach leverages the complementary strengths of different data sources to enhance accuracy, robustness, and generalisability in applications ranging from natural language processing and computer vision to healthcare diagnostics and autonomous systems.
What is multimodal in machine learning?
In the context of machine learning, “multimodal” refers to the integration of data from multiple modalities or sources, such as text, images, audio, and video. Multimodal deep learning involves developing models that can effectively process and analyse information from different types of data simultaneously. By combining insights from various modalities, these models can offer a more comprehensive understanding of the underlying patterns and relationships within the data, leading to enhanced performance in tasks like image recognition, speech recognition, sentiment analysis, and more.
What is multimodal approach in deep learning?
A multimodal approach in deep learning refers to the integration of data from multiple modalities, such as text, images, audio, and video, into a single model for more comprehensive analysis and understanding. By combining information from different sources, multimodal deep learning models can capture richer insights and patterns that may not be apparent when considering each modality in isolation. This approach allows for more nuanced and contextually relevant results in tasks such as image captioning, sentiment analysis, autonomous driving, healthcare diagnostics, and more.
What are multimodal deep learning challenges?
One of the frequently asked questions about multimodal deep learning is regarding the challenges it poses. Multimodal deep learning faces several hurdles, including the need to synchronise data from different modalities, handle varying data formats, manage computational complexity due to processing multiple types of data simultaneously, address issues related to large-scale datasets, and ensure model interpretability. Researchers are actively working on overcoming these challenges through innovative approaches and techniques to enhance the effectiveness and efficiency of multimodal deep learning systems.
What is an example of a multimodal data?
An example of multimodal data is a social media post that contains both text and images. In this scenario, the text provides contextual information or a caption, while the image conveys visual content related to the text. By combining these two modalities, multimodal deep learning algorithms can extract meaningful insights and understand the relationship between the textual and visual components of the data. This integration of multiple modalities enables more comprehensive analysis and interpretation of complex information, making multimodal data a valuable resource for various applications in artificial intelligence and machine learning.