
Exploring the Foundations: Traditional Machine Learning Techniques
23 September 2024
Traditional Machine Learning: An Overview
Machine learning has become a cornerstone of modern technology, enabling computers to learn from data and make intelligent decisions. While recent advances in deep learning and neural networks have garnered significant attention, traditional machine learning techniques remain fundamental to the field. This article explores the basics of traditional machine learning, its key algorithms, and its applications.
What is Traditional Machine Learning?
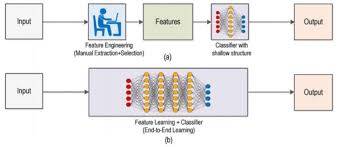
Traditional machine learning refers to a set of algorithms and statistical models that enable computers to perform tasks without explicit instructions. These algorithms learn patterns from data and use these patterns to make predictions or decisions. Unlike deep learning, which relies on neural networks with many layers, traditional machine learning often involves simpler models that are easier to interpret and require less computational power.
Key Algorithms in Traditional Machine Learning
Linear Regression
Linear regression is one of the most basic and widely used algorithms in machine learning. It models the relationship between a dependent variable and one or more independent variables by fitting a linear equation to observed data. This technique is commonly used for predictive analysis.
Logistic Regression
Logistic regression is used for binary classification problems where the outcome is either true or false (0 or 1). It estimates the probability that a given input belongs to a particular class by applying a logistic function.
Decision Trees
A decision tree is a flowchart-like model that makes decisions based on a series of questions about the input features. Each internal node represents a test on an attribute, each branch represents an outcome of the test, and each leaf node represents a class label or continuous value.
Support Vector Machines (SVM)
SVMs are powerful classifiers that work by finding the hyperplane that best separates different classes in the feature space. They are effective in high-dimensional spaces and are widely used for both classification and regression tasks.
K-Nearest Neighbours (KNN)
KNN is an instance-based algorithm that classifies new data points based on their similarity to known data points. The ‘k’ refers to the number of nearest neighbours considered when making predictions.
Applications of Traditional Machine Learning
The versatility of traditional machine learning algorithms has led to their adoption across various domains:
- Finance: Credit scoring, fraud detection, algorithmic trading.
- Healthcare: Disease prediction, patient risk assessment, personalised treatment plans.
- E-commerce: Product recommendations, customer segmentation, inventory management.
- Agriculture: Crop yield prediction, pest detection, soil health monitoring.
- Email Filtering: Spam detection and categorisation of emails into folders.
The Future of Traditional Machine Learning
While deep learning continues to push boundaries in fields like image recognition and natural language processing, traditional machine learning remains relevant due to its simplicity and effectiveness for many practical problems. As computational resources become more accessible and datasets grow larger, traditional machine learning techniques will continue to evolve and integrate with newer technologies.
The synergy between traditional methods and modern advancements ensures that machine learning will remain at the forefront of technological innovation for years to come.
Essential Tips for Optimising Traditional Machine Learning Models
- Preprocess your data to handle missing values and scale numerical features.
- Split your data into training and testing sets to evaluate the performance of your model.
- Choose the appropriate algorithm based on the type of problem you are trying to solve.
- Tune hyperparameters to improve the performance of your model.
- Evaluate your model using metrics such as accuracy, precision, recall, and F1 score.
Preprocess your data to handle missing values and scale numerical features.
When working with traditional machine learning algorithms, it is essential to preprocess your data effectively to ensure accurate model performance. One important tip is to handle missing values and scale numerical features before training your model. By addressing missing data through techniques like imputation or removal, and scaling numerical features to a consistent range, you can enhance the quality of your dataset and improve the overall effectiveness of your machine learning model. This preprocessing step plays a crucial role in preparing the data for successful training and achieving reliable results in traditional machine learning tasks.
Split your data into training and testing sets to evaluate the performance of your model.
When working with traditional machine learning algorithms, it is crucial to split your data into training and testing sets. This practice allows you to train your model on a subset of the data and then evaluate its performance on unseen data. By doing so, you can assess how well your model generalises to new data and avoid overfitting. Splitting the data helps ensure that your model’s performance is reliable and provides valuable insights into its effectiveness in real-world scenarios.
Choose the appropriate algorithm based on the type of problem you are trying to solve.
When delving into traditional machine learning, it is crucial to select the most suitable algorithm that aligns with the specific nature of the problem at hand. The choice of algorithm plays a pivotal role in determining the accuracy and efficiency of the model. By understanding the characteristics of different algorithms and matching them to the problem’s requirements, one can enhance the overall performance and effectiveness of the machine learning solution. Therefore, selecting the appropriate algorithm based on the type of problem being addressed is a fundamental step towards achieving successful outcomes in traditional machine learning applications.
Tune hyperparameters to improve the performance of your model.
Tuning hyperparameters is a crucial step in traditional machine learning to enhance the performance of your model. Hyperparameters are settings that govern the learning process and directly impact the model’s ability to generalise well to unseen data. By carefully adjusting these hyperparameters through techniques like grid search or random search, you can fine-tune your model to achieve optimal accuracy and efficiency. This iterative process of hyperparameter tuning plays a significant role in maximising the predictive power of your traditional machine learning algorithms and ultimately improving the overall performance of your models.
Evaluate your model using metrics such as accuracy, precision, recall, and F1 score.
When working with traditional machine learning models, it is crucial to evaluate their performance using a range of metrics such as accuracy, precision, recall, and F1 score. These metrics provide valuable insights into how well the model is performing in terms of correctly identifying and predicting outcomes. Accuracy measures the overall correctness of predictions, precision indicates the proportion of true positive predictions among all positive predictions, recall measures the proportion of actual positives that were correctly identified, and the F1 score combines precision and recall into a single metric to provide a balanced assessment of model performance. By analysing these metrics, you can gain a comprehensive understanding of your model’s effectiveness and make informed decisions for further refinement and improvement.