
Unleashing the Power of Machine Learning Algorithms: Exploring the Future of Artificial Intelligence
16 November 2023
Machine Learning Algorithms: Unleashing the Power of Artificial Intelligence
In today’s digital age, the term “machine learning” has become increasingly prevalent. From self-driving cars to personalized recommendations on streaming platforms, machine learning algorithms are at the heart of many cutting-edge technologies. But what exactly are these algorithms, and how do they work?
At its core, machine learning is a branch of artificial intelligence that enables computers to learn from data and improve their performance without being explicitly programmed. This is achieved through the use of sophisticated algorithms that can analyze vast amounts of data, identify patterns, and make predictions or decisions based on that information.
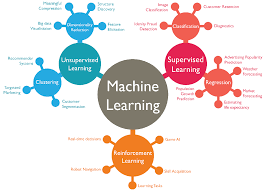
There are several types of machine learning algorithms, each with its own unique characteristics and applications. Let’s explore some of the most commonly used ones:
- Supervised Learning: This algorithm learns from labeled data, where input examples are paired with corresponding desired outputs. By analyzing these pairs, the algorithm can learn to predict outputs for new inputs accurately. Supervised learning is widely used in tasks such as image recognition, speech recognition, and spam detection.
- Unsupervised Learning: In contrast to supervised learning, unsupervised learning deals with unlabeled data. The algorithm explores the data to discover underlying patterns or structures without any predefined output labels. Clustering and anomaly detection are common applications of unsupervised learning.
- Reinforcement Learning: Inspired by behavioral psychology, reinforcement learning involves an agent interacting with an environment and receiving feedback in the form of rewards or penalties based on its actions. Through trial-and-error exploration, the algorithm learns to maximize rewards by making optimal decisions in a given context. Reinforcement learning has been successfully applied to game-playing agents and autonomous robotics.
- Deep Learning: Deep learning algorithms mimic the structure and function of human neural networks by utilizing multiple layers of artificial neurons called “artificial neural networks.” These networks can process vast amounts of complex data such as images or text, enabling tasks such as image recognition, natural language processing, and speech synthesis.
Machine learning algorithms are not limited to these four types. There are also ensemble methods that combine multiple algorithms to improve performance and hybrid models that incorporate elements from different algorithm families.
The potential applications of machine learning algorithms are vast and ever-expanding. They have revolutionized various industries, including healthcare, finance, marketing, and cybersecurity. From predicting diseases based on medical records to detecting fraudulent transactions in real-time, the impact of machine learning is undeniable.
However, it’s important to note that machine learning algorithms are not infallible. They heavily rely on the quality and quantity of the data available for training. Biases in data or incorrect assumptions can lead to flawed predictions or reinforce existing biases. Therefore, it is crucial to ensure ethical considerations and responsible practices when developing and deploying machine learning models.
In conclusion, machine learning algorithms form the backbone of modern artificial intelligence systems. They have transformed industries by enabling computers to learn from data and make intelligent decisions. As technology continues to advance at an unprecedented pace, we can expect machine learning algorithms to play an increasingly significant role in shaping our future.
Advantages of Machine Learning Algorithms: Enhanced Precision, Automated Processes, Cost Efficiency, Scalability, and Enhanced Decision-Making
Challenges of Machine Learning Algorithms: A Closer Look at Cost, Time, Rigidity, Data Dependency, and the Black Box Problem
Increased Accuracy
Increased Accuracy: The Power of Machine Learning Algorithms
Machine learning algorithms have revolutionized the way we analyze and make predictions from data. One of the key advantages they bring to the table is their ability to achieve increased accuracy compared to traditional methods.
Traditional methods often rely on manual analysis or predefined rules to make predictions or decisions. While these approaches can be effective in some cases, they may struggle when faced with complex or large datasets. This is where machine learning algorithms shine.
By leveraging statistical techniques, machine learning algorithms can automatically identify patterns and relationships within vast amounts of data. They learn from this data and use it to make predictions or decisions with remarkable accuracy. This ability to uncover hidden patterns that may not be apparent to human analysts allows machine learning algorithms to surpass traditional methods in terms of accuracy.
The statistical nature of machine learning algorithms enables them to adapt and improve over time as more data becomes available. They can continuously learn from new information, refine their models, and enhance their predictive capabilities. This iterative process helps them achieve even higher levels of accuracy as they gain more experience with the data.
Furthermore, machine learning algorithms excel at handling complex datasets with numerous variables or intricate relationships between variables. They can effectively capture non-linear dependencies and interactions that may be challenging for traditional approaches to discern. By considering a multitude of factors simultaneously, these algorithms can provide more nuanced and accurate predictions.
The increased accuracy offered by machine learning algorithms has far-reaching implications across various fields. In healthcare, for example, these algorithms can assist in diagnosing diseases based on medical records, lab results, and patient characteristics, leading to more precise treatment plans.
In finance, machine learning algorithms analyze vast amounts of market data to predict stock prices or detect fraudulent transactions in real-time. Their ability to identify subtle patterns helps financial institutions make informed decisions while minimizing risks.
Moreover, in customer service and marketing, machine learning algorithms enable personalized recommendations based on individual preferences and behaviors. By understanding customer preferences, businesses can tailor their offerings and improve customer satisfaction.
It is important to note that the accuracy of machine learning algorithms heavily relies on the quality and diversity of the data used for training. Biases or inaccuracies in the training data can lead to biased or inaccurate predictions. Therefore, it is crucial to ensure that the data used is representative and free from biases.
In conclusion, machine learning algorithms offer a significant advantage in terms of increased accuracy compared to traditional methods. By leveraging statistical techniques and analyzing vast amounts of data, these algorithms uncover hidden patterns and relationships that enhance their predictive capabilities. As technology continues to advance, we can expect machine learning algorithms to further improve accuracy and transform various industries with their powerful capabilities.
Automation
Automation: Empowering Efficiency and Innovation with Machine Learning Algorithms
In today’s fast-paced world, time is a valuable resource. One significant advantage of machine learning algorithms is their ability to automate tedious and repetitive tasks, liberating human potential for more meaningful and creative work.
Traditionally, many tasks have required substantial manual effort, consuming valuable time and resources. However, with the advent of machine learning algorithms, these tasks can now be automated, leading to increased efficiency and productivity.
By leveraging the power of data analysis and pattern recognition, machine learning algorithms can quickly process vast amounts of information and make accurate predictions or decisions. This automation capability has a broad range of applications across industries.
For example, in customer service, chatbots powered by machine learning algorithms can handle routine inquiries and provide instant responses 24/7. This not only improves customer satisfaction but also allows human agents to focus on more complex or specialized customer needs.
In manufacturing, machine learning algorithms can optimize production processes by analyzing data from sensors and making real-time adjustments. This enables companies to increase output while reducing errors and downtime.
Moreover, in the field of data analysis itself, machine learning algorithms can automate the extraction of insights from large datasets. By automating this process, businesses can save significant time and resources that would otherwise be spent on manual data exploration.
The automation capabilities of machine learning algorithms extend beyond routine tasks. They can also assist in decision-making processes by providing valuable insights based on historical data analysis. This empowers businesses to make informed decisions quickly and accurately.
By automating tedious tasks through machine learning algorithms, individuals and organizations gain the freedom to focus on more meaningful work. This includes activities that require critical thinking, problem-solving skills, creativity, innovation, and building relationships with customers or colleagues.
Furthermore, automation opens up new possibilities for innovation. With the burden of repetitive tasks lifted off their shoulders, professionals have more time to explore new ideas and develop innovative solutions that drive progress and growth.
However, it’s important to note that while automation brings numerous benefits, it should be implemented thoughtfully. Human oversight and intervention are still essential to ensure the accuracy and ethical implications of automated processes.
In conclusion, machine learning algorithms offer the remarkable advantage of automation. By automating tedious tasks, these algorithms empower individuals and organizations to focus on more meaningful and innovative work. As technology continues to advance, the potential for automation through machine learning algorithms will only increase, revolutionizing industries and unlocking new possibilities for human potential.
Cost-Effective
Cost-Effective: How Machine Learning Algorithms Revolutionize Business Efficiency
In the fast-paced world of business, finding ways to increase efficiency and reduce costs is always a top priority. This is where machine learning algorithms come into play, offering a significant advantage for businesses seeking to streamline their operations. One notable pro of these algorithms is their cost-effectiveness, as they automate processes and help save money on labor expenses.
Traditionally, many tasks required human intervention, consuming valuable time and resources. However, with the advent of machine learning algorithms, businesses can now automate repetitive or data-intensive processes that were previously performed manually. This automation not only saves time but also reduces the need for extensive human involvement.
By leveraging machine learning algorithms, businesses can process vast amounts of data quickly and accurately. These algorithms are designed to analyze data patterns, identify trends, and make predictions or decisions based on the information at hand. This eliminates the need for manual data analysis, which can be time-consuming and prone to errors.
Moreover, automating processes through machine learning algorithms reduces dependence on human labor. By replacing certain manual tasks with automated systems, businesses can significantly cut down on labor costs. This allows companies to allocate their resources more efficiently and focus on higher-value activities that require human expertise.
For example, in customer service operations, machine learning algorithms can be employed to automate responses to frequently asked questions or common issues. By using natural language processing and sentiment analysis techniques, these algorithms can understand customer queries and provide accurate responses in real-time. This not only improves customer satisfaction but also reduces the need for dedicated customer service representatives to handle routine inquiries.
Additionally, machine learning algorithms can optimize supply chain management by analyzing historical data and predicting future demand patterns. By automating inventory management and demand forecasting processes, businesses can minimize stockouts or overstocking situations while maximizing operational efficiency.
The cost-effectiveness of machine learning algorithms goes beyond saving on labor expenses alone; it extends to overall business productivity. By automating repetitive tasks, employees can redirect their focus towards more strategic and creative activities that add value to the organization. This can lead to increased innovation, improved decision-making, and enhanced customer experiences.
In conclusion, machine learning algorithms offer a cost-effective solution for businesses aiming to increase efficiency and reduce labor costs. By automating processes that were traditionally performed manually, these algorithms streamline operations, optimize resource allocation, and enable companies to make data-driven decisions quickly. Embracing the power of machine learning algorithms allows businesses to unlock their full potential while staying competitive in today’s rapidly evolving marketplace.
Scalability
Scalability: Machine Learning Algorithms and the Power of Big Data
In today’s digital landscape, the amount of data being generated is growing at an exponential rate. From social media interactions to sensor data from IoT devices, businesses and organizations are faced with the challenge of extracting valuable insights from this vast sea of information. This is where machine learning algorithms truly shine, offering a remarkable advantage in terms of scalability.
One significant pro of machine learning algorithms is their ability to process large amounts of data quickly and accurately. Traditional methods of data analysis often struggle to handle massive datasets efficiently, leading to time-consuming processes and potential information loss. However, machine learning algorithms have been specifically designed to tackle these challenges head-on.
By leveraging parallel processing techniques and distributed computing frameworks, machine learning algorithms can seamlessly scale up to handle big data projects. These algorithms can process enormous volumes of structured and unstructured data in a fraction of the time it would take traditional methods. This scalability empowers businesses to extract valuable insights from their data more efficiently and make informed decisions in real-time.
Moreover, the accuracy and reliability of machine learning algorithms remain intact even when dealing with massive datasets. By analyzing patterns within the data, these algorithms can identify correlations, trends, and anomalies that may have otherwise gone unnoticed. This capability opens up new possibilities for businesses across various industries, such as personalized marketing campaigns, fraud detection systems, predictive maintenance models, and much more.
The scalability offered by machine learning algorithms not only accelerates data analysis but also enables organizations to uncover hidden patterns that can drive innovation and improve operational efficiency. It allows businesses to harness the power of big data without being overwhelmed by its sheer volume.
However, it’s important to note that scalability does come with its own set of challenges. As datasets grow larger, computational resources become increasingly crucial for efficient processing. Organizations must invest in robust infrastructure capable of handling the demands imposed by big data projects.
In conclusion, the scalability of machine learning algorithms is a significant advantage in the era of big data. By efficiently processing large volumes of data, these algorithms empower businesses to uncover valuable insights and make data-driven decisions in real-time. As technology continues to evolve, machine learning algorithms will undoubtedly play a pivotal role in transforming the way organizations leverage the power of their data.
Improved Decision Making
Improved Decision Making: Unleashing the Power of Machine Learning Algorithms
In today’s data-driven world, businesses are constantly seeking ways to gain a competitive edge. One significant advantage that machine learning algorithms bring to the table is their ability to improve decision making. By analyzing vast amounts of data quickly and efficiently, these algorithms provide accurate insights into customer behavior and market trends, enabling businesses to make informed decisions with confidence.
Traditionally, decision-making processes have relied on human intuition and experience. While valuable, these methods often fall short when dealing with large datasets that are beyond human capacity to analyze comprehensively. This is where machine learning algorithms step in, offering a powerful solution.
With their ability to process enormous volumes of data in real-time, machine learning algorithms can identify patterns and correlations that may not be immediately apparent to human analysts. By uncovering hidden insights from complex datasets, these algorithms empower businesses to make data-driven decisions based on factual evidence rather than gut feelings or assumptions.
One area where machine learning algorithms excel is in understanding customer behavior. By analyzing vast amounts of customer data such as purchase history, browsing patterns, and social media interactions, these algorithms can identify trends and preferences with remarkable accuracy. This information allows businesses to personalize their marketing efforts, tailor product offerings, and optimize customer experiences.
Moreover, machine learning algorithms can also help businesses stay ahead of market trends. By continuously monitoring market conditions and analyzing relevant data from various sources such as industry reports and social media sentiment analysis, these algorithms can identify emerging trends or shifts in consumer preferences early on. Armed with this knowledge, businesses can adapt their strategies proactively and seize opportunities before their competitors.
Another key advantage of machine learning algorithms is their ability to automate decision-making processes. Once trained on historical data and validated against real-world outcomes, these algorithms can be deployed in automated systems or integrated into existing business processes. This not only saves time but also reduces the risk of human error or bias, ensuring consistent and objective decision making.
However, it’s important to note that machine learning algorithms are not a silver bullet. They rely heavily on the quality and relevance of the data provided. Therefore, businesses must invest in data collection, cleaning, and validation processes to ensure the accuracy and reliability of the insights generated by these algorithms.
In conclusion, machine learning algorithms offer an unprecedented opportunity for businesses to improve their decision-making processes. By analyzing large amounts of data quickly and accurately, these algorithms provide valuable insights into customer behavior and market trends. With this knowledge at their disposal, businesses can make informed decisions that drive growth, enhance customer satisfaction, and stay one step ahead in an increasingly competitive landscape.
Costly
The Costly Conundrum of Machine Learning Algorithms
While machine learning algorithms have gained immense popularity for their ability to revolutionize industries, it’s important to acknowledge the potential downsides. One significant challenge that organizations face when implementing machine learning algorithms is the associated costs.
Implementing machine learning algorithms can be a costly affair, requiring substantial investments in hardware, software, and personnel. Let’s delve into some of the key cost factors:
- Infrastructure: Machine learning algorithms often demand powerful computational resources to process vast amounts of data and perform complex calculations. This necessitates investing in high-performance hardware such as GPUs (Graphics Processing Units) or specialized processors. Additionally, scaling up infrastructure to accommodate growing data volumes can add to the expenses.
- Data Collection and Preparation: Machine learning algorithms rely on large quantities of high-quality data for training and validation. Collecting and curating this data can be a time-consuming and expensive process. Organizations may need to invest in data acquisition tools or collaborate with external sources to gather relevant datasets.
- Skilled Workforce: Building and maintaining machine learning models requires a team of skilled professionals with expertise in areas such as data science, programming, and algorithm development. Hiring or training personnel proficient in these domains can be costly due to the scarcity of skilled individuals in the field.
- Model Development and Iteration: Developing effective machine learning models requires extensive experimentation, testing, and refinement. This iterative process involves significant time and effort from both data scientists and domain experts who collaborate closely to fine-tune the algorithms. The costs associated with this continuous development cycle can accumulate over time.
- Maintenance and Updates: Machine learning models are not static entities; they require ongoing maintenance, updates, and monitoring for optimal performance. Ensuring that models remain accurate, reliable, and secure involves regular checks, bug fixes, feature updates, and adaptation to evolving business requirements.
To mitigate these costs, organizations often need careful planning, budgeting, and strategic decision-making. Prioritizing investments based on specific business needs, considering cloud-based solutions for infrastructure, and leveraging open-source frameworks can help manage expenses.
Despite the initial costs, it’s crucial to recognize that machine learning algorithms have the potential to provide substantial returns on investment. They can unlock valuable insights, automate complex processes, enhance decision-making capabilities, and drive innovation within organizations.
In conclusion, while the costs associated with implementing machine learning algorithms may pose a challenge, organizations need to assess the long-term benefits and potential competitive advantages they can bring. By carefully managing resources and making informed decisions, businesses can navigate the costly conundrum of machine learning algorithms and harness their transformative power.
Time-consuming
Time-consuming: The Drawback of Training Machine Learning Algorithms
Machine learning algorithms have undoubtedly revolutionized the way we process and analyze data, but they are not without their drawbacks. One significant con of these algorithms is the time it takes to train them.
Training a machine learning algorithm involves feeding it with a large dataset and allowing it to learn patterns and make predictions based on that data. However, this process can be time-consuming, especially when dealing with extensive datasets or complex models.
The time required for training depends on various factors, such as the size and complexity of the dataset, the chosen algorithm, and the computational resources available. In some cases, training a machine learning algorithm can take hours, days, or even weeks to complete.
The time-consuming nature of training poses challenges in several ways. Firstly, it hampers productivity as developers and researchers need to wait for the training process to finish before they can evaluate the performance of their models or make improvements. This delay can slow down progress in developing new applications or refining existing ones.
Moreover, the time required for training also affects scalability. As datasets continue to grow exponentially in size and complexity, it becomes increasingly challenging to train machine learning algorithms within reasonable timeframes. This limitation can hinder the deployment of real-time applications that require immediate responses or decision-making.
Addressing this con is an ongoing challenge for researchers and developers in the field. Efforts are being made to optimize algorithms and develop more efficient training techniques that reduce computation time without compromising accuracy. Additionally, advancements in hardware technology, such as specialized graphics processing units (GPUs) and distributed computing systems, are helping to accelerate training processes.
While training machine learning algorithms may be time-consuming currently, it’s important to note that this drawback does not overshadow their potential benefits. Despite the challenges posed by lengthy training times, machine learning continues to push boundaries across various industries and contribute to advancements in areas like healthcare diagnostics, self-driving cars, and natural language processing.
In conclusion, the time-consuming nature of training machine learning algorithms is a significant drawback that needs to be acknowledged. However, ongoing research and technological advancements are continuously addressing this issue, paving the way for faster and more efficient training processes. As the field progresses, we can expect to see improvements that mitigate the time constraints associated with training machine learning algorithms.
Rigidity
Rigidity: The Limitation of Machine Learning Algorithms
Machine learning algorithms have undoubtedly revolutionized the field of artificial intelligence, enabling computers to learn from data and make accurate predictions. However, like any technology, they come with their limitations. One significant drawback is their inherent rigidity in problem-solving.
Machine learning algorithms are designed to follow a predefined set of rules and patterns based on the data they have been trained on. While this rigidity ensures consistency and reliability in their predictions, it also restricts their ability to adapt to changing conditions or inputs.
In real-world scenarios, conditions can evolve rapidly, and new information can emerge that may alter the dynamics of a problem. Machine learning algorithms often struggle to handle these situations effectively. They lack the flexibility to incorporate new data or adjust their models accordingly.
This limitation becomes particularly evident in dynamic environments where the relationships between variables change over time. For instance, in financial markets, where stock prices are influenced by numerous factors, machine learning algorithms may struggle to adapt quickly enough to capture sudden market shifts or unexpected events.
Moreover, machine learning algorithms heavily rely on historical data for training. If the training data does not adequately represent all possible scenarios or if it contains biases or inaccuracies, the algorithm’s rigid nature can perpetuate those shortcomings and lead to flawed predictions.
To address this rigidity issue, researchers are actively exploring methods such as online learning and transfer learning. Online learning allows algorithms to continuously update their models as new data becomes available, enabling them to adapt gradually over time. Transfer learning aims to leverage knowledge learned from one domain and apply it to another related domain, allowing for more flexible adaptation.
While these advancements show promise in mitigating rigidity concerns, it is essential for developers and practitioners of machine learning algorithms to be aware of this limitation. They must carefully consider whether the problem at hand requires a more adaptable approach rather than relying solely on rigid models.
In conclusion, while machine learning algorithms have proven their worth in various applications, their rigidity remains a significant con. As technology advances, finding ways to enhance their flexibility and adaptability will be crucial for unlocking the full potential of machine learning and ensuring its effectiveness in an ever-changing world.
Data Dependency
Data Dependency: A Challenge in Machine Learning Algorithms
Machine learning algorithms have undoubtedly revolutionized numerous industries, but they are not without their limitations. One significant con that plagues these algorithms is their heavy reliance on data. The accuracy of the results produced by the algorithm is highly dependent on the quality, completeness, and accuracy of the data it is trained on.
In an ideal scenario, machine learning algorithms require large datasets that encompass a wide range of scenarios and variations. These datasets serve as the foundation for training the algorithm to recognize patterns, make predictions, or perform specific tasks. However, if the data used for training is incomplete or inaccurate, it can significantly impact the reliability and effectiveness of the algorithm’s output.
Incomplete data refers to situations where certain attributes or variables are missing from the dataset. This can occur due to various reasons like human error during data collection or technical limitations. When important features are missing from the dataset, the algorithm may struggle to identify crucial patterns or make accurate predictions.
Similarly, inaccurate data poses a significant challenge for machine learning algorithms. If the dataset contains errors, outliers, or misleading information, it can skew the algorithm’s understanding of patterns and relationships within the data. Consequently, this can lead to flawed predictions or inaccurate results.
Data dependency also introduces challenges when dealing with dynamic environments. Machine learning models trained on historical data might struggle to adapt to new trends or changes in real-time scenarios. As a result, their performance may deteriorate over time if not regularly updated with fresh and relevant data.
To mitigate these challenges associated with data dependency in machine learning algorithms, several strategies can be employed. Firstly, ensuring rigorous data preprocessing techniques can help identify and handle missing values appropriately. Imputation methods such as mean imputation or regression imputation can be used to fill in missing values based on available information.
Additionally, performing thorough data validation and verification processes before training an algorithm is crucial. This involves carefully examining each piece of data for accuracy, removing outliers or erroneous entries, and addressing any inconsistencies or biases that may be present.
Furthermore, ongoing monitoring and updating of the algorithm’s performance using new data can help identify and rectify any drift or degradation in accuracy over time. Regular retraining of the algorithm with updated datasets ensures that it remains effective in dynamic environments.
While data dependency poses a challenge for machine learning algorithms, it is essential to recognize that it is not an insurmountable obstacle. With proper data management practices, careful preprocessing techniques, and continuous monitoring and updating, the impact of incomplete or inaccurate data can be mitigated to a significant extent.
In conclusion, the accuracy and effectiveness of machine learning algorithms are heavily reliant on the quality and completeness of the data they are trained on. Data dependency presents a challenge that needs to be carefully addressed through robust data preprocessing techniques, validation processes, and ongoing monitoring. By doing so, we can enhance the reliability and performance of machine learning algorithms in real-world applications.
Black Box Problem
Black Box Problem: Unveiling the Mystery of Machine Learning Algorithms
Machine learning algorithms have undoubtedly revolutionized various industries, but they are not without their challenges. One significant drawback is what is often referred to as the “black box problem.” This issue arises from the inherent difficulty in interpreting how machine learning algorithms make decisions.
Unlike traditional rule-based systems where decisions can be traced back to explicit rules or logic, machine learning algorithms operate in a more complex and opaque manner. They process vast amounts of data, learn patterns, and make predictions or decisions based on that information. However, understanding exactly how they arrive at those conclusions can be a daunting task.
The lack of visibility into the internal workings of machine learning algorithms poses several challenges. Firstly, it becomes challenging to debug these algorithms when something goes wrong with their output. Without knowing the underlying processes and factors that influenced their decision-making, it can be challenging to identify and rectify errors or biases.
Moreover, the black box nature of machine learning algorithms raises concerns about transparency and accountability. In critical applications such as healthcare or autonomous vehicles, it is crucial to understand why a particular decision was made. However, without insight into the inner workings of the algorithm, it becomes difficult to provide explanations or justifications for its actions.
The black box problem also poses ethical dilemmas. If an algorithm produces biased or discriminatory outcomes, it becomes challenging to identify and address those issues without understanding how the algorithm arrived at its decisions. This lack of interpretability can perpetuate existing biases in data or inadvertently introduce new ones.
Efforts are underway to address this challenge by developing methods for interpreting and explaining machine learning models. Techniques such as feature importance analysis and model-agnostic interpretability aim to shed light on why certain decisions were made. Researchers are also exploring ways to make machine learning algorithms more transparent and explainable by design.
In conclusion, while machine learning algorithms offer tremendous potential for innovation and advancement, their black box nature presents significant challenges. The lack of interpretability and visibility into their decision-making processes can hinder debugging, transparency, and accountability. As the field of machine learning continues to evolve, it is crucial to develop solutions that strike a balance between the power of these algorithms and the need for interpretability and explainability. Only then can we fully harness the potential of machine learning while ensuring trust and ethical use in various domains.