
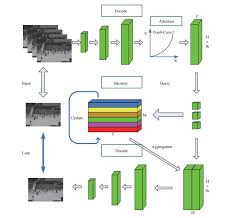
Exploring Anomaly Detection Through Deep Learning
10 October 2024
Anomaly Detection with Deep Learning
Deep learning, a subset of artificial intelligence, has revolutionised many fields with its ability to learn complex patterns from data. Anomaly detection, a crucial task in various industries such as finance, cybersecurity, and healthcare, can greatly benefit from the power of deep learning algorithms.
Traditional anomaly detection methods often struggle to detect subtle or complex anomalies in datasets. Deep learning models, on the other hand, excel at capturing intricate patterns and relationships within data, making them well-suited for anomaly detection tasks.
One popular approach to anomaly detection using deep learning is the use of autoencoders. Autoencoders are neural networks designed to reconstruct input data at the output layer. During training, an autoencoder learns to encode and decode normal data accurately. When presented with anomalous data during inference, the reconstruction error is typically higher, indicating the presence of an anomaly.
Another effective deep learning technique for anomaly detection is the use of generative adversarial networks (GANs). GANs consist of two neural networks – a generator and a discriminator – that compete against each other. The generator creates synthetic data samples while the discriminator’s role is to distinguish between real and synthetic data. Anomalies can be detected by observing discrepancies in how well the discriminator distinguishes between normal and anomalous data.
Deep learning models offer flexibility and scalability in anomaly detection tasks. By leveraging the power of neural networks and large-scale datasets, organisations can improve their ability to detect anomalies quickly and accurately.
In conclusion, anomaly detection with deep learning presents exciting opportunities for various industries to enhance their monitoring and security systems. As deep learning continues to advance, we can expect even more sophisticated techniques to emerge for detecting anomalies in diverse datasets.
9 Essential Tips for Effective Anomaly Detection Using Deep Learning
- Understand the problem domain and data characteristics before choosing a deep learning model for anomaly detection.
- Preprocess the data effectively by handling missing values, scaling features, and removing noise to improve model performance.
- Consider using autoencoders, variational autoencoders (VAEs), or generative adversarial networks (GANs) for anomaly detection tasks.
- Experiment with different architectures, activation functions, and hyperparameters to fine-tune the deep learning model for optimal results.
- Use techniques like transfer learning to leverage pre-trained models and limited labelled data for training anomaly detection models.
- Regularly monitor and update the deep learning model to adapt to evolving patterns in data and detect new anomalies effectively.
- Evaluate the model performance using appropriate metrics such as precision, recall, F1 score, ROC curve, and AUC-ROC to assess its effectiveness in anomaly detection.
- Combine deep learning with traditional machine learning algorithms like isolation forests or one-class SVMs for improved accuracy in detecting anomalies.
- Interpret the results of the deep learning model by analysing false positives/negatives and understanding why certain instances are flagged as anomalies.
Understand the problem domain and data characteristics before choosing a deep learning model for anomaly detection.
To effectively leverage deep learning for anomaly detection, it is essential to first understand the specific problem domain and the characteristics of the data at hand. By gaining insights into the nature of anomalies that may occur and the patterns present in the data, one can make informed decisions when selecting a deep learning model. This preliminary understanding allows for the appropriate customisation and tuning of the model to better suit the unique requirements of the anomaly detection task, ultimately enhancing its accuracy and effectiveness in detecting anomalies within the dataset.
Preprocess the data effectively by handling missing values, scaling features, and removing noise to improve model performance.
To enhance the performance of deep learning models for anomaly detection, it is crucial to preprocess the data effectively. This involves handling missing values, scaling features, and removing noise from the dataset. By addressing missing values through imputation or removal strategies, scaling features to a consistent range, and eliminating noise that could introduce inaccuracies, the model can better capture underlying patterns and anomalies in the data. Effective preprocessing lays a solid foundation for the deep learning model to achieve optimal performance in detecting anomalies accurately and efficiently.
Consider using autoencoders, variational autoencoders (VAEs), or generative adversarial networks (GANs) for anomaly detection tasks.
When tackling anomaly detection tasks, it is advisable to explore the use of advanced deep learning techniques such as autoencoders, variational autoencoders (VAEs), or generative adversarial networks (GANs). These models offer sophisticated capabilities to capture complex patterns and anomalies within datasets. Autoencoders are effective in learning data representations and detecting anomalies based on reconstruction errors. VAEs enhance this by incorporating probabilistic modelling, enabling a more robust understanding of data variability. GANs, on the other hand, leverage adversarial training to generate synthetic data and differentiate between normal and anomalous instances. By utilising these powerful deep learning architectures, organisations can enhance their anomaly detection systems with improved accuracy and efficiency.
Experiment with different architectures, activation functions, and hyperparameters to fine-tune the deep learning model for optimal results.
To enhance the effectiveness of anomaly detection using deep learning, it is advisable to experiment with various architectures, activation functions, and hyperparameters. Fine-tuning these aspects of the deep learning model can significantly improve its performance and accuracy in identifying anomalies within datasets. By exploring different configurations and parameters, researchers and practitioners can optimise the model to achieve superior results and better adapt to the intricacies of the data being analysed.
Use techniques like transfer learning to leverage pre-trained models and limited labelled data for training anomaly detection models.
To enhance anomaly detection using deep learning, utilising techniques such as transfer learning can be highly beneficial. By leveraging pre-trained models and limited labelled data, organisations can expedite the training process and improve the performance of anomaly detection models. Transfer learning allows the model to transfer knowledge learned from one task to another, enabling it to adapt to new datasets with minimal labelled data. This approach not only saves time and resources but also enhances the accuracy and efficiency of anomaly detection systems.
Regularly monitor and update the deep learning model to adapt to evolving patterns in data and detect new anomalies effectively.
To enhance the effectiveness of anomaly detection using deep learning, it is essential to regularly monitor and update the deep learning model. By doing so, the model can adapt to evolving patterns in the data and improve its ability to detect new anomalies effectively. Continuous monitoring and updating of the model ensure that it remains accurate and relevant in identifying anomalies in dynamic datasets, ultimately enhancing the overall performance of the anomaly detection system.
Evaluate the model performance using appropriate metrics such as precision, recall, F1 score, ROC curve, and AUC-ROC to assess its effectiveness in anomaly detection.
When implementing anomaly detection using deep learning, it is crucial to evaluate the model’s performance using a range of appropriate metrics. Metrics such as precision, recall, F1 score, ROC curve, and AUC-ROC provide valuable insights into the effectiveness of the model in detecting anomalies. Precision measures the proportion of correctly identified anomalies out of all anomalies detected, while recall calculates the proportion of actual anomalies that were correctly identified by the model. The F1 score combines precision and recall to provide a balanced assessment of the model’s performance. Additionally, analysing the ROC curve and calculating the area under the curve (AUC-ROC) can help assess how well the model distinguishes between normal and anomalous data points. By utilising these metrics, one can gain a comprehensive understanding of the model’s efficacy in anomaly detection tasks.
Combine deep learning with traditional machine learning algorithms like isolation forests or one-class SVMs for improved accuracy in detecting anomalies.
Combining deep learning with traditional machine learning algorithms such as isolation forests or one-class SVMs can significantly enhance the accuracy of anomaly detection. Deep learning models excel at capturing complex patterns in data, while traditional algorithms like isolation forests and one-class SVMs are effective at identifying outliers and anomalies. By integrating these approaches, organisations can leverage the strengths of both techniques to achieve more robust and accurate anomaly detection results. This hybrid approach allows for a comprehensive analysis of data, leading to improved anomaly detection performance and better insights into potential threats or irregularities within datasets.
Interpret the results of the deep learning model by analysing false positives/negatives and understanding why certain instances are flagged as anomalies.
When implementing anomaly detection using deep learning models, it is crucial to interpret the results by analysing false positives and false negatives. Understanding why certain instances are flagged as anomalies can provide valuable insights into the performance of the model and help refine its accuracy. By investigating the reasons behind these misclassifications, such as data noise or model limitations, practitioners can enhance the model’s ability to distinguish between normal and anomalous patterns effectively. This analytical approach not only improves the reliability of anomaly detection systems but also deepens our understanding of how deep learning algorithms perceive and classify data anomalies.