
Unleashing the Potential of Convolutional Neural Networks in Artificial Intelligence
12 May 2024
The Power of Convolutional Neural Networks
Convolutional Neural Networks (CNNs) have revolutionized the field of artificial intelligence and machine learning. These deep learning algorithms are specifically designed to process visual data, making them highly effective in tasks such as image recognition, object detection, and facial recognition.
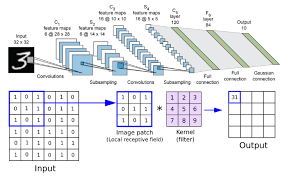
The key feature that sets CNNs apart from traditional neural networks is their ability to automatically learn hierarchical features from raw pixel data. This is achieved through the use of convolutional layers, pooling layers, and fully connected layers.
Convolutional layers apply filters to input images to extract features such as edges, textures, and shapes. Pooling layers then downsample the feature maps to reduce computational complexity while retaining important information. Finally, fully connected layers combine the extracted features to make predictions.
One of the most notable applications of CNNs is in image classification tasks. By training a CNN on a large dataset of labelled images, the network can learn to accurately classify new images into predefined categories. This has led to significant advancements in areas such as medical imaging, autonomous vehicles, and security systems.
Furthermore, CNNs have also been successfully applied in natural language processing tasks such as text classification and sentiment analysis. By treating text data as an image with one dimension (sequence of words), CNNs can extract meaningful features and patterns from textual information.
In conclusion, Convolutional Neural Networks represent a powerful tool in the realm of artificial intelligence, enabling machines to process visual and textual data with remarkable accuracy and efficiency. As research continues to advance in this field, we can expect even more groundbreaking applications of CNNs in various domains.
9 Practical Tips for Enhancing Convolutional Neural Network Performance
- Use ReLU activation functions to speed up training and help mitigate the vanishing gradient problem.
- Apply data augmentation techniques to expand your dataset and reduce overfitting.
- Start with pre-trained models when working on a new task to leverage transfer learning, saving time and resources.
- Regularise your network with dropout layers or L2 regularisation to prevent overfitting.
- Utilise batch normalisation to stabilise learning and reduce the number of epochs required for training.
- Optimise filter sizes, pooling layers, and layer depths for your specific application for better performance.
- Monitor performance metrics such as accuracy, precision, recall, and F1-score rather than just loss values during training and validation phases.
- Experiment with different optimisers like Adam or SGD with momentum depending on the problem complexity and dataset size.
- Ensure that your input data is normalised or standardised so that the model can learn more effectively from it.
Use ReLU activation functions to speed up training and help mitigate the vanishing gradient problem.
When working with Convolutional Neural Networks, utilising Rectified Linear Unit (ReLU) activation functions can significantly enhance the training process and address the issue of the vanishing gradient problem. By incorporating ReLU activation functions, which introduce non-linearity into the network by allowing only positive values to pass through, training can be accelerated due to faster convergence and reduced computational complexity. Moreover, ReLU helps prevent the vanishing gradient problem by avoiding saturation in neurons, enabling more efficient learning and improved model performance.
Apply data augmentation techniques to expand your dataset and reduce overfitting.
To enhance the performance and generalization of your Convolutional Neural Network, it is advisable to implement data augmentation techniques. By applying methods such as rotation, flipping, scaling, and adding noise to your existing dataset, you can effectively increase the diversity of training examples. This not only expands your dataset but also helps in reducing overfitting by exposing the model to a wider range of variations in the input data. Data augmentation plays a crucial role in improving the robustness and accuracy of CNN models, making them more adept at handling real-world scenarios with varying conditions and perspectives.
Start with pre-trained models when working on a new task to leverage transfer learning, saving time and resources.
When embarking on a new task involving convolutional neural networks, it is advisable to begin with pre-trained models to harness the benefits of transfer learning. By leveraging existing models that have been trained on vast datasets, you can expedite the learning process, conserve valuable time, and optimise available resources. Transfer learning allows you to adapt pre-trained models to suit your specific task by fine-tuning them with your own dataset, ultimately enhancing the efficiency and effectiveness of your neural network implementation.
Regularise your network with dropout layers or L2 regularisation to prevent overfitting.
Regularising your Convolutional Neural Network with dropout layers or L2 regularisation is essential to prevent overfitting. Overfitting occurs when a model learns the training data too well, leading to poor generalisation on unseen data. Dropout layers randomly deactivate a certain percentage of neurons during training, forcing the network to learn more robust and generalisable features. On the other hand, L2 regularisation adds a penalty term to the loss function, discouraging large weights and promoting simpler models. By incorporating these techniques into your CNN architecture, you can improve its performance and ensure that it generalises well to new data.
Utilise batch normalisation to stabilise learning and reduce the number of epochs required for training.
By utilising batch normalisation in convolutional neural networks, you can significantly improve the stability of learning and reduce the number of epochs needed for training. Batch normalisation helps to standardise the inputs to each layer by normalising them to have zero mean and unit variance. This prevents the model from getting stuck in local minima during training and allows for faster convergence towards optimal solutions. Implementing batch normalisation in CNNs not only enhances the efficiency of the learning process but also contributes to better overall performance and generalisation of the network.
Optimise filter sizes, pooling layers, and layer depths for your specific application for better performance.
To enhance the performance of your Convolutional Neural Network, it is crucial to optimise filter sizes, pooling layers, and layer depths according to the requirements of your specific application. By carefully selecting appropriate filter sizes, you can effectively capture relevant features in the input data. Choosing the right pooling layers allows for efficient downsampling while preserving essential information. Additionally, adjusting layer depths ensures that the network can learn complex patterns and relationships within the data, ultimately leading to improved performance tailored to your unique application needs.
Monitor performance metrics such as accuracy, precision, recall, and F1-score rather than just loss values during training and validation phases.
When working with Convolutional Neural Networks, it is essential to monitor performance metrics such as accuracy, precision, recall, and F1-score throughout the training and validation phases. While tracking loss values provides insights into model convergence, evaluating these additional metrics offers a more comprehensive understanding of the network’s performance. Accuracy indicates the proportion of correctly classified instances, precision measures the ratio of true positive predictions to all positive predictions, recall assesses the ability to identify relevant instances, and the F1-score combines precision and recall into a single metric. By focusing on these key performance indicators alongside loss values, developers can gain a more nuanced assessment of their CNN model’s effectiveness in handling complex tasks like image recognition or object detection.
Experiment with different optimisers like Adam or SGD with momentum depending on the problem complexity and dataset size.
When working with convolutional neural networks, it is essential to experiment with different optimisers such as Adam or SGD with momentum, depending on the complexity of the problem and the size of the dataset. Optimisers play a crucial role in training neural networks by adjusting the model’s parameters to minimise the loss function. Adam, known for its adaptive learning rates, is suitable for a wide range of problems and can converge quickly. On the other hand, SGD with momentum can help navigate through local minima more effectively and is beneficial for larger datasets. By exploring and selecting the right optimiser based on specific requirements, one can enhance the performance and efficiency of convolutional neural networks in various applications.
Ensure that your input data is normalised or standardised so that the model can learn more effectively from it.
To maximise the effectiveness of your Convolutional Neural Network, it is crucial to normalise or standardise your input data. By ensuring that the data is on a consistent scale, the model can learn more efficiently and effectively extract meaningful features from the images. Normalisation or standardisation helps in speeding up the training process, improving convergence, and ultimately enhancing the accuracy of predictions made by the CNN.