
Unleashing the Potential: Deep-Learning Revolutionizes Artificial Intelligence
02 December 2023
Deep Learning: Unlocking the Power of Artificial Intelligence
In recent years, deep learning has emerged as a groundbreaking technology that is revolutionizing the field of artificial intelligence (AI). With its ability to process and analyze vast amounts of data, deep learning has opened up new possibilities and applications across various industries.
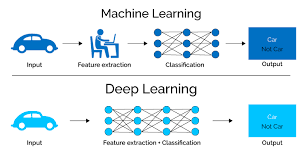
At its core, deep learning is a subset of machine learning that focuses on training artificial neural networks to learn and make intelligent decisions. These neural networks are inspired by the structure and function of the human brain, consisting of interconnected layers of artificial neurons.
One of the key advantages of deep learning lies in its ability to automatically extract features from raw data, eliminating the need for manual feature engineering. This allows deep learning models to learn directly from complex and unstructured data such as images, audio, and text. As a result, deep learning has achieved remarkable success in tasks such as image recognition, speech recognition, natural language processing, and even autonomous driving.
The power of deep learning lies in its ability to learn hierarchical representations. Deep neural networks can learn multiple layers of abstraction, enabling them to understand complex patterns and relationships within the data. This hierarchical representation allows for better accuracy and performance compared to traditional machine learning algorithms.
One notable example of deep learning’s impact is in the field of healthcare. Deep learning models have been developed to assist in diagnosing diseases from medical images such as X-rays or MRIs. By analyzing millions of medical images and their corresponding diagnoses, these models can learn patterns that are often imperceptible to human eyes. This has the potential to revolutionize medical diagnostics by providing more accurate and timely diagnoses.
Another area where deep learning has made significant strides is natural language processing (NLP). Deep neural networks can be trained on vast amounts of textual data, allowing them to understand language semantics and generate human-like responses. This has led to advancements in chatbots, virtual assistants, and machine translation systems that can accurately translate between languages.
However, it’s important to acknowledge that deep learning is not without its challenges. Training deep neural networks requires substantial computational resources and large amounts of labeled data. Additionally, interpretability and explainability of deep learning models remain active areas of research.
Despite these challenges, the potential of deep learning is undeniable. Its ability to learn from raw data and make intelligent decisions has transformed various industries, including healthcare, finance, retail, and more. As technology continues to advance, deep learning will undoubtedly play a pivotal role in shaping the future of AI.
In conclusion, deep learning has unlocked the power of artificial intelligence by enabling machines to learn from complex data and make intelligent decisions. Its ability to automatically extract features and learn hierarchical representations has led to breakthroughs in various fields. As we continue to explore the possibilities of AI, deep learning will undoubtedly remain at the forefront of innovation and drive us towards a more intelligent future.
7 Essential Tips for Deep Learning Success in English (UK)
- Start by understanding the fundamentals of deep learning and related concepts such as machine learning, artificial intelligence, and neural networks.
- Familiarise yourself with popular deep learning frameworks such as TensorFlow, Keras, PyTorch and Caffe.
- Learn how to use GPU for training deep learning models – GPUs are much faster than CPUs for training large models.
- Understand the basics of data pre-processing for deep learning models – this includes feature engineering and normalisation techniques such as min-max scaling or z-scoring.
- Experiment with different network architectures to find the best model for your problem – this could include convolutional neural networks (CNNs) or recurrent neural networks (RNNs).
- Make sure you have enough data to train a robust model – if you don’t have enough data, consider using transfer learning or generative adversarial networks (GANs).
- Monitor your model’s performance during training and use techniques such as early stopping or hyperparameter tuning to improve it further if needed
Start by understanding the fundamentals of deep learning and related concepts such as machine learning, artificial intelligence, and neural networks.
Deep learning has become one of the most important areas of research in the field of artificial intelligence. It is a form of machine learning that uses algorithms to simulate the way the human brain works. Deep learning is used for many applications such as image recognition, speech recognition, natural language processing, and more.
In order to get started with deep learning, it is important to first understand the fundamentals of deep learning and related concepts such as machine learning, artificial intelligence, and neural networks. Machine learning is a subset of artificial intelligence that focuses on developing systems that can learn from data without being explicitly programmed. Neural networks are networks of interconnected nodes that are used to process data in a way similar to how neurons work in the human brain.
Once you have a basic understanding of these concepts, you can start exploring different types of deep learning algorithms such as convolutional neural networks (CNNs), recurrent neural networks (RNNs), and generative adversarial networks (GANs). Each type has its own advantages and disadvantages which should be considered when choosing an algorithm for your project. Additionally, there are many open-source libraries available which can help simplify the development process.
Finally, it is important to remember that deep learning is an ongoing process and requires continuous experimentation and improvement. By understanding the fundamentals and continuing to explore new techniques, you will be able to create powerful models that can tackle complex problems.
Familiarise yourself with popular deep learning frameworks such as TensorFlow, Keras, PyTorch and Caffe.
Deep learning is an exciting area of artificial intelligence that has been gaining a lot of momentum in recent years. It is a type of machine learning algorithm that uses multiple layers of artificial neurons to process data and make decisions. In order to get the most out of deep learning, it is important to be familiar with popular deep learning frameworks such as TensorFlow, Keras, PyTorch and Caffe.
TensorFlow is an open source software library for numerical computation developed by Google. It has become one of the most popular frameworks for deep learning due to its flexibility and scalability. TensorFlow can be used for a variety of tasks such as image classification, natural language processing and time series analysis.
Keras is an open source neural network library written in Python that runs on top of other popular deep learning libraries such as TensorFlow and Theano. It provides a simple interface for building neural networks and allows developers to quickly prototype their ideas without having to delve into the underlying algorithms.
PyTorch is another open source framework developed by Facebook’s AI Research Lab. It provides a more intuitive approach to building neural networks than TensorFlow or Keras, making it easier for developers with limited experience in deep learning to get started quickly.
Finally, Caffe is an open source deep learning framework developed by the Berkeley Vision and Learning Center at UC Berkeley. It has been used extensively in computer vision applications such as image classification and object detection.
By familiarising yourself with these popular deep learning frameworks, you will be able to develop powerful models quickly and efficiently, allowing you to take advantage of the latest advances in artificial intelligence technology.
Learn how to use GPU for training deep learning models – GPUs are much faster than CPUs for training large models.
Deep learning has revolutionised the way we process data and make predictions. By harnessing the power of neural networks, deep learning models can learn from data to make accurate predictions. One of the most important aspects of deep learning is training these models to learn from data.
Traditionally, CPUs (Central Processing Units) have been used to train deep learning models, but GPUs (Graphics Processing Units) are becoming increasingly popular due to their speed and efficiency. GPUs are much faster than CPUs for training large models and can significantly reduce training time.
If you want to take advantage of the speed and efficiency offered by GPUs for training your deep learning models, you need to learn how to use them properly. This involves understanding how GPUs work and what hardware is required for optimal performance. You also need to be familiar with software tools such as TensorFlow or PyTorch, which are used for building deep learning models on GPUs.
Fortunately, there are plenty of resources available online that can help you get started with GPU-based deep learning. With some practice and dedication, you can quickly become an expert in using GPU for training your deep learning models efficiently.
Understand the basics of data pre-processing for deep learning models – this includes feature engineering and normalisation techniques such as min-max scaling or z-scoring.
When it comes to building effective deep learning models, understanding the importance of data pre-processing is key. Data pre-processing involves preparing and transforming raw data to enhance its quality and make it suitable for training deep learning models. One crucial aspect of data pre-processing is feature engineering, which involves selecting and creating relevant features from the available data.
Feature engineering plays a vital role in deep learning as it helps extract meaningful information from the input data. By carefully selecting or creating features, we can improve the model’s ability to learn and make accurate predictions. This process requires domain knowledge and an understanding of the problem at hand.
Additionally, normalisation techniques are commonly applied during data pre-processing for deep learning models. Two popular normalisation techniques are min-max scaling and z-scoring. Min-max scaling rescales the feature values to a specific range, typically between 0 and 1. This technique is useful when there are significant variations in feature scales, ensuring that all features contribute equally to the model’s learning process.
Z-scoring, also known as standardisation, transforms the feature values by subtracting the mean and dividing by the standard deviation. This technique helps in achieving zero mean and unit variance for each feature. Standardisation is particularly useful when dealing with features that have different units or distributions.
By applying these normalisation techniques, we ensure that our deep learning models are not biased towards certain features due to differences in their scales or distributions. Normalising the data helps create a level playing field for all features, allowing the model to focus on extracting meaningful patterns rather than being influenced by irrelevant variations.
Understanding data pre-processing techniques like feature engineering and normalisation is crucial for building robust deep learning models. It allows us to harness the full potential of our data by enhancing its quality and ensuring that our models can learn effectively.
In conclusion, mastering the basics of data pre-processing for deep learning models is essential for achieving optimal performance. Feature engineering and normalisation techniques like min-max scaling and z-scoring play a significant role in preparing data for deep learning tasks. By carefully selecting or creating features and normalising the data, we can improve the model’s ability to learn and make accurate predictions. So, invest time in understanding these techniques, as they will undoubtedly contribute to your success in the world of deep learning.
Experiment with different network architectures to find the best model for your problem – this could include convolutional neural networks (CNNs) or recurrent neural networks (RNNs).
Unlocking the Potential of Deep Learning: Experimenting with Network Architectures
Deep learning has revolutionized the field of artificial intelligence, offering powerful tools to solve complex problems. When it comes to building successful deep learning models, one crucial tip stands out: experiment with different network architectures to find the best model for your specific problem.
Network architecture refers to the structure and arrangement of layers within a deep neural network. It determines how information flows through the network and how it is processed. Two popular types of network architectures are convolutional neural networks (CNNs) and recurrent neural networks (RNNs).
Convolutional neural networks (CNNs) are commonly used for tasks involving image recognition, computer vision, and pattern detection. CNNs are designed to automatically learn spatial hierarchies by applying filters or kernels on input data. These filters detect features at different levels of abstraction, allowing CNNs to recognize complex patterns in images.
On the other hand, recurrent neural networks (RNNs) excel in tasks that involve sequential or time-series data. RNNs have a unique ability to retain memory of past information, making them ideal for tasks such as natural language processing, speech recognition, and machine translation. RNNs process input data sequentially while maintaining an internal state that captures contextual information.
By experimenting with different network architectures like CNNs and RNNs, you can leverage the strengths of each architecture to tackle specific problems effectively. It’s important to consider the nature of your data and the requirements of your task when selecting an architecture.
When experimenting with network architectures, it’s advisable to start with simpler models and gradually increase complexity as needed. This allows you to understand how different architectural choices impact model performance. Additionally, consider factors such as the number of layers, activation functions, regularization techniques, and optimization algorithms when designing your models.
The process of finding the best model for your problem often involves a combination of trial-and-error experimentation and careful evaluation. It’s crucial to establish proper evaluation metrics and validation techniques to assess the performance of different architectures accurately.
Remember, there is no one-size-fits-all solution in deep learning. Each problem is unique, and the best model architecture may vary depending on the specific requirements and characteristics of your task. By investing time in experimenting with different network architectures, you can uncover hidden insights and unlock the full potential of deep learning for your problem.
In conclusion, deep learning offers immense potential for solving complex problems in various domains. To maximize the effectiveness of your models, it is crucial to experiment with different network architectures such as CNNs or RNNs. By exploring these architectural options and understanding their strengths, you can tailor your models to specific tasks and achieve remarkable results. Embrace the power of experimentation, and let it guide you towards finding the best deep learning model for your unique problem.
Make sure you have enough data to train a robust model – if you don’t have enough data, consider using transfer learning or generative adversarial networks (GANs).
Deep Learning Tip: The Importance of Sufficient Data for Robust Models
When it comes to deep learning, having enough data is crucial for training robust models that can make accurate predictions. Without an adequate amount of data, models may struggle to generalize well and may not achieve the desired level of performance. However, if you find yourself facing a scarcity of data, there are alternative techniques that can help overcome this challenge.
One approach to tackle limited data is transfer learning. Transfer learning leverages pre-trained models that have been trained on large datasets and have learned general features applicable to various tasks. By using a pre-trained model as a starting point, you can take advantage of the knowledge it has gained from its extensive training on vast amounts of data. Fine-tuning the pre-trained model with your specific dataset allows it to adapt and learn task-specific features more efficiently.
Another technique that can be employed in situations with limited data is generative adversarial networks (GANs). GANs consist of two neural networks: a generator and a discriminator. The generator network learns to generate synthetic data samples that resemble the real data, while the discriminator network learns to distinguish between real and synthetic samples. Through an iterative process, both networks improve their performance, resulting in the generation of realistic synthetic samples that can be used to augment the original dataset.
By utilizing transfer learning or GANs, you can effectively enhance your model’s performance even when faced with limited data. These techniques provide valuable alternatives for training deep learning models in scenarios where collecting large amounts of labeled data may be challenging or time-consuming.
However, it’s important to note that while these methods can help mitigate the impact of limited data, they are not magical solutions that guarantee perfect results. It’s still necessary to carefully evaluate and validate the performance of models trained with these techniques.
In summary, having enough high-quality data is essential for training robust deep learning models. When faced with limited data, considering transfer learning or leveraging GANs can be effective strategies to augment your dataset and improve model performance. These techniques allow you to leverage the knowledge from pre-trained models or generate synthetic data samples, enabling your models to learn better representations and make more accurate predictions.
Monitor your model’s performance during training and use techniques such as early stopping or hyperparameter tuning to improve it further if needed
Enhancing Deep Learning Models: The Importance of Monitoring and Iteration
Deep learning models have revolutionized the field of artificial intelligence, enabling us to tackle complex problems and achieve remarkable results. However, building an effective deep learning model is not a one-time task; it requires continuous monitoring and fine-tuning to optimize its performance.
One crucial tip in the journey of deep learning is to monitor your model’s performance during training. By closely observing how your model learns from the data, you can gain valuable insights into its strengths and weaknesses. This monitoring process involves analyzing metrics such as accuracy, loss, or validation scores at regular intervals.
Monitoring allows you to identify potential issues early on. For example, if you notice that your model’s accuracy plateaus or starts to decline during training, it might indicate overfitting or underfitting. Overfitting occurs when the model performs well on the training data but fails to generalize to new data. Underfitting, on the other hand, suggests that the model is not capturing enough complexity from the data.
To address these issues and improve your model’s performance further, two techniques come into play: early stopping and hyperparameter tuning.
Early stopping is a method where training is stopped if there is no improvement in the validation metrics for a certain number of epochs. This helps prevent overfitting by finding an optimal balance between underfitting and overfitting. By stopping the training at an appropriate time, you can ensure that your model generalizes well to unseen data.
Hyperparameter tuning involves adjusting various parameters that influence the learning process of your deep learning model. These parameters include learning rate, batch size, number of layers in neural networks, etc. By systematically exploring different combinations of these hyperparameters, you can find configurations that lead to better performance and faster convergence.
There are several techniques available for hyperparameter tuning such as grid search or random search methods. These techniques help you efficiently explore the hyperparameter space and find the best combination that maximizes your model’s performance.
By incorporating these techniques into your deep learning workflow, you can iteratively improve your model’s performance. Continuously monitoring and fine-tuning your model ensures that it adapts to the data and performs optimally.
In conclusion, monitoring your deep learning model’s performance during training and utilizing techniques like early stopping and hyperparameter tuning are crucial steps in achieving superior results. These practices allow you to identify potential issues early on, prevent overfitting or underfitting, and optimize your model’s performance. With a vigilant approach to monitoring and iteration, you can unlock the full potential of deep learning models and drive innovation in the field of artificial intelligence.