
Exploring the Power of Supervised Learning in Neural Networks
24 September 2024
Supervised Learning in Neural Networks
Supervised learning is a fundamental concept in the realm of machine learning and artificial intelligence. It involves training a model on a labelled dataset, meaning that each training example is paired with an output label. In the context of neural networks, supervised learning plays a pivotal role in enabling these models to perform tasks such as classification, regression, and more.
Understanding Supervised Learning
In supervised learning, the goal is to learn a mapping from input features to output labels. This process begins with a dataset that includes both the inputs (features) and their corresponding outputs (labels). The neural network uses this data to learn patterns and relationships between the inputs and outputs.
The process can be broken down into several key steps:
- Data Collection: Gather a comprehensive dataset that includes input-output pairs relevant to the task at hand.
- Data Preprocessing: Clean and preprocess the data to ensure it is suitable for training. This may involve normalising values, handling missing data, and splitting the dataset into training and testing sets.
- Model Selection: Choose an appropriate neural network architecture based on the complexity of the task. Common architectures include feedforward neural networks, convolutional neural networks (CNNs), and recurrent neural networks (RNNs).
- Training: Train the neural network using the labelled dataset. During training, the model adjusts its weights based on the error between its predictions and the actual labels. This adjustment process is typically done using backpropagation and optimisation algorithms like stochastic gradient descent (SGD).
- Evaluation: Assess the performance of the trained model on a separate validation or test dataset to ensure it generalises well to new data.
- Tuning: Fine-tune hyperparameters such as learning rate, batch size, and network architecture to improve model performance.
The Role of Neural Networks
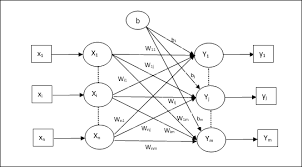
Neural networks are powerful tools for supervised learning due to their ability to approximate complex functions. They consist of layers of interconnected nodes or neurons that process input features through weighted connections. Each layer applies non-linear transformations to capture intricate patterns within the data.
The primary components of a neural network include:
- Input Layer: Receives raw input features from the dataset.
- Hidden Layers: Consist of multiple layers where each neuron applies an activation function to introduce non-linearity into the model. These layers learn hierarchical representations of data.
- Output Layer:
The Training Process
The training process involves iteratively updating weights within neurons using optimisation techniques like backpropagation combined with gradient descent. Here’s how it works:
// Pseudo-code for backpropagation
for each epoch:
for each batch:
forward pass: compute predictions
compute loss: measure error between predictions & true labels
backward pass: propagate error backwards through network
update weights: adjust parameters using gradients
Error Calculation
A loss function quantifies how well predicted outputs match actual labels during training iterations by measuring errors such as mean squared error (MSE) or cross-entropy loss depending upon problem type – regression/classification respectively .
Backpropagation
Backward propagation computes gradients w.r.t loss function enabling weight updates via chain rule differentiation ensuring minimal error convergence across epochs .
Optimisation Algorithms
Stochastic Gradient Descent(SGD), Adam & RMSprop are popular choices adjusting weights efficiently towards optimal solutions reducing overall computational cost/time complexity involved during extensive iterative processes .
Applications & Benefits
Supervised learning finds applications across various domains including image recognition , natural language processing(NLP) , medical diagnosis , financial forecasting among others leveraging vast amounts labelled datasets driving innovation/accuracy levels unprecedented heights previously unattainable traditional methods alone .
Benefits :
- < strong > High Accuracy : Well-trained models achieve high accuracy levels compared conventional algorithms due inherent ability capture complex relationships within data effectively .
- < strong > Automation : Automates decision-making processes reducing human intervention/errors significantly improving efficiency/productivity overall operations involved respective fields/domains concerned .
- < strong > Scalability : Scalable architectures handle large-scale datasets seamlessly adapting evolving requirements dynamically ensuring robustness/flexibility desired outcomes achieved consistently over time periods concerned .
Top 6 Tips for Effective Supervised Learning with Neural Networks
- Ensure you have labelled training data for supervised learning.
- Choose the appropriate neural network architecture for your task.
- Split your dataset into training and validation sets to evaluate model performance.
- Regularize your neural network to prevent overfitting.
- Monitor the learning process by visualising metrics such as loss and accuracy.
- Fine-tune hyperparameters like learning rate and batch size for optimal performance.
Ensure you have labelled training data for supervised learning.
It is essential to ensure that you have labelled training data when embarking on supervised learning in neural networks. Labelled data pairs each input with its corresponding output, providing the model with the necessary information to learn and make predictions accurately. Without labelled training data, the neural network would lack the guidance needed to understand the relationships between inputs and outputs, hindering its ability to learn effectively. Therefore, by ensuring you have labelled training data, you set a strong foundation for your neural network to acquire knowledge and improve its performance in various tasks such as classification and regression.
Choose the appropriate neural network architecture for your task.
When embarking on a supervised learning task in neural networks, it is crucial to carefully select the appropriate neural network architecture that aligns with the complexities of the specific task at hand. The choice of architecture, whether it be a feedforward neural network, convolutional neural network (CNN), or recurrent neural network (RNN), plays a significant role in determining the model’s capacity to learn and generalise patterns within the data. By choosing the right architecture, tailored to the nature of the problem being solved, one can enhance the efficiency and effectiveness of the neural network in producing accurate predictions and insightful outcomes.
Split your dataset into training and validation sets to evaluate model performance.
To enhance the effectiveness of supervised learning in neural networks, it is crucial to split your dataset into training and validation sets. By doing so, you can evaluate the performance of your model on unseen data and prevent overfitting. The training set is used to train the neural network on labelled examples, while the validation set helps assess how well the model generalises to new data. This practice allows for fine-tuning hyperparameters and adjusting the model’s architecture to improve its overall performance and ensure reliable predictions in real-world scenarios.
Regularize your neural network to prevent overfitting.
Regularisation is a crucial technique in neural network training to prevent overfitting. By incorporating regularisation methods such as L1 or L2 regularization, dropout, or early stopping, you can effectively control the complexity of your model and improve its generalisation capabilities. Regularising your neural network helps to reduce the risk of memorising noise in the training data and encourages the model to learn meaningful patterns that can be applied to unseen data. Prioritising regularisation in your neural network training process is essential for achieving better performance and robustness in real-world applications.
Monitor the learning process by visualising metrics such as loss and accuracy.
Monitoring the learning process in a neural network through visualising metrics like loss and accuracy is a crucial tip in supervised learning. By keeping a close eye on these metrics, one can gain valuable insights into how well the model is performing during training. Loss indicates the difference between predicted outputs and actual labels, helping to assess the model’s predictive power. On the other hand, accuracy provides a measure of how often the model’s predictions match the true labels. Visualising these metrics allows for real-time tracking of the model’s progress, enabling adjustments to be made to improve performance and enhance overall learning outcomes.
Fine-tune hyperparameters like learning rate and batch size for optimal performance.
To enhance the performance of a neural network model in supervised learning, it is crucial to fine-tune key hyperparameters such as the learning rate and batch size. Adjusting the learning rate controls the magnitude of weight updates during training, impacting the speed and quality of convergence. Similarly, modifying the batch size influences the efficiency of gradient computations and can affect the model’s ability to generalise to new data. By carefully tuning these hyperparameters, researchers and practitioners can optimise the neural network’s performance, leading to improved accuracy and robustness in various machine learning tasks.
Top 6 Tips for Effective Supervised Learning with Neural Networks
- Ensure you have labelled training data for supervised learning.
- Choose the appropriate neural network architecture for your task.
- Split your dataset into training and validation sets to evaluate model performance.
- Regularize your neural network to prevent overfitting.
- Monitor the learning process by visualising metrics such as loss and accuracy.
- Fine-tune hyperparameters like learning rate and batch size for optimal performance.
Ensure you have labelled training data for supervised learning.
It is essential to ensure that you have labelled training data when embarking on supervised learning in neural networks. Labelled data pairs each input with its corresponding output, providing the model with the necessary information to learn and make predictions accurately. Without labelled training data, the neural network would lack the guidance needed to understand the relationships between inputs and outputs, hindering its ability to learn effectively. Therefore, by ensuring you have labelled training data, you set a strong foundation for your neural network to acquire knowledge and improve its performance in various tasks such as classification and regression.
Choose the appropriate neural network architecture for your task.
When embarking on a supervised learning task in neural networks, it is crucial to carefully select the appropriate neural network architecture that aligns with the complexities of the specific task at hand. The choice of architecture, whether it be a feedforward neural network, convolutional neural network (CNN), or recurrent neural network (RNN), plays a significant role in determining the model’s capacity to learn and generalise patterns within the data. By choosing the right architecture, tailored to the nature of the problem being solved, one can enhance the efficiency and effectiveness of the neural network in producing accurate predictions and insightful outcomes.
Split your dataset into training and validation sets to evaluate model performance.
To enhance the effectiveness of supervised learning in neural networks, it is crucial to split your dataset into training and validation sets. By doing so, you can evaluate the performance of your model on unseen data and prevent overfitting. The training set is used to train the neural network on labelled examples, while the validation set helps assess how well the model generalises to new data. This practice allows for fine-tuning hyperparameters and adjusting the model’s architecture to improve its overall performance and ensure reliable predictions in real-world scenarios.
Regularize your neural network to prevent overfitting.
Regularisation is a crucial technique in neural network training to prevent overfitting. By incorporating regularisation methods such as L1 or L2 regularization, dropout, or early stopping, you can effectively control the complexity of your model and improve its generalisation capabilities. Regularising your neural network helps to reduce the risk of memorising noise in the training data and encourages the model to learn meaningful patterns that can be applied to unseen data. Prioritising regularisation in your neural network training process is essential for achieving better performance and robustness in real-world applications.
Monitor the learning process by visualising metrics such as loss and accuracy.
Monitoring the learning process in a neural network through visualising metrics like loss and accuracy is a crucial tip in supervised learning. By keeping a close eye on these metrics, one can gain valuable insights into how well the model is performing during training. Loss indicates the difference between predicted outputs and actual labels, helping to assess the model’s predictive power. On the other hand, accuracy provides a measure of how often the model’s predictions match the true labels. Visualising these metrics allows for real-time tracking of the model’s progress, enabling adjustments to be made to improve performance and enhance overall learning outcomes.
Fine-tune hyperparameters like learning rate and batch size for optimal performance.
To enhance the performance of a neural network model in supervised learning, it is crucial to fine-tune key hyperparameters such as the learning rate and batch size. Adjusting the learning rate controls the magnitude of weight updates during training, impacting the speed and quality of convergence. Similarly, modifying the batch size influences the efficiency of gradient computations and can affect the model’s ability to generalise to new data. By carefully tuning these hyperparameters, researchers and practitioners can optimise the neural network’s performance, leading to improved accuracy and robustness in various machine learning tasks.