
Exploring the Depths of Supervised and Unsupervised Learning in Machine Learning
12 July 2025
Supervised Learning and Unsupervised Learning
In the field of machine learning, two fundamental approaches are widely used: supervised learning and unsupervised learning. Let’s delve into the differences between these two methods and explore their applications.
Supervised Learning
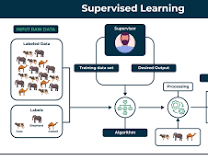
Supervised learning is a type of machine learning where the model is trained on labelled data. In other words, the algorithm learns from input-output pairs provided during the training phase. The goal of supervised learning is to predict the output based on input data.
Common examples of supervised learning include classification and regression tasks. In classification, the algorithm categorises data into predefined classes, while in regression, it predicts continuous values.
Unsupervised Learning
Unsupervised learning, on the other hand, involves training models on unlabelled data. The algorithm explores patterns and relationships within the data without explicit guidance on the output. Clustering and dimensionality reduction are common applications of unsupervised learning.
Clustering algorithms group similar data points together based on their features, while dimensionality reduction techniques aim to reduce the complexity of data by extracting essential features.
Applications
Supervised learning is widely used in various fields, such as image recognition, natural language processing, and financial forecasting. By providing labelled data for training, supervised models can make accurate predictions on new unseen data.
Unsupervised learning finds applications in anomaly detection, market segmentation, and recommendation systems. By uncovering hidden patterns in unlabelled data, unsupervised algorithms can reveal valuable insights for decision-making.
Conclusion
In conclusion, supervised learning relies on labelled data for training predictive models, while unsupervised learning uncovers patterns in unlabelled data without explicit guidance. Both approaches play a crucial role in advancing machine learning technologies and finding innovative solutions across various domains.
7 Essential Tips for Mastering Supervised and Unsupervised Learning Techniques
- 1. Ensure you have labelled training data for supervised learning.
- 2. Choose appropriate evaluation metrics to assess the performance of your supervised learning model.
- 3. Split your data into training and testing sets to evaluate the generalisation ability of your model.
- 4. Consider using cross-validation techniques to validate the robustness of your supervised learning model.
- 5. Be cautious of overfitting when training a supervised learning model by tuning hyperparameters.
- 7. Continuously monitor and update your supervised learning model with new data to maintain its accuracy.
- 1. Preprocess your data by scaling or normalising features before applying unsupervised learning algorithms.
1. Ensure you have labelled training data for supervised learning.
To effectively utilise supervised learning algorithms, it is essential to ensure that you have labelled training data. Labelled data provides the necessary input-output pairs for the algorithm to learn and make predictions accurately. By meticulously annotating and organising your training data with appropriate labels, you enable the model to generalise patterns and relationships, ultimately enhancing its predictive capabilities. This foundational step is crucial in setting the stage for successful supervised learning applications across various domains.
2. Choose appropriate evaluation metrics to assess the performance of your supervised learning model.
When working with supervised learning models, it is essential to select suitable evaluation metrics to gauge the performance accurately. By choosing appropriate metrics, such as accuracy, precision, recall, F1 score, or area under the ROC curve, you can assess how well your model is predicting outcomes based on the labelled data. These evaluation metrics provide valuable insights into the model’s strengths and weaknesses, helping you fine-tune its performance and make informed decisions about its effectiveness in real-world applications.
3. Split your data into training and testing sets to evaluate the generalisation ability of your model.
To enhance the performance of your machine learning model in both supervised and unsupervised learning tasks, it is essential to follow the tip of splitting your data into training and testing sets. By dividing your dataset into these subsets, you can evaluate the generalisation ability of your model effectively. The training set allows the model to learn patterns and relationships from the data, while the testing set serves as a benchmark to assess how well the model can predict on unseen data. This practice helps prevent overfitting and provides valuable insights into the model’s performance and accuracy, ensuring its reliability in real-world applications.
4. Consider using cross-validation techniques to validate the robustness of your supervised learning model.
When working with supervised learning models, it is essential to consider using cross-validation techniques to assess the robustness and generalisation ability of your model. Cross-validation helps in evaluating how well the model will perform on unseen data by splitting the dataset into multiple subsets for training and testing. By validating the model through cross-validation, you can gain insights into its performance across different data samples and ensure its reliability in making accurate predictions.
5. Be cautious of overfitting when training a supervised learning model by tuning hyperparameters.
When training a supervised learning model, it is crucial to be cautious of overfitting, especially when tuning hyperparameters. Overfitting occurs when a model learns the training data too well, capturing noise and irrelevant patterns that do not generalise to unseen data. By carefully tuning hyperparameters, such as adjusting the model complexity or regularisation techniques, you can prevent overfitting and ensure that your model performs well on new data. Striking the right balance between model performance and generalisation is key to building robust supervised learning models.
7. Continuously monitor and update your supervised learning model with new data to maintain its accuracy.
Continuously monitoring and updating your supervised learning model with new data is essential to ensure its accuracy and relevance over time. By incorporating fresh data into the model, you can adapt to changing patterns and trends in the underlying dataset, ultimately improving the model’s performance and predictive capabilities. This iterative process of updating the model enables you to stay ahead of evolving patterns in the data and make more informed decisions based on the most up-to-date information available.
1. Preprocess your data by scaling or normalising features before applying unsupervised learning algorithms.
Before applying unsupervised learning algorithms, it is essential to preprocess your data by scaling or normalising features. This step is crucial to ensure that the input data is on a consistent scale and that the algorithms can effectively identify patterns and relationships within the dataset. Scaling or normalising features helps in avoiding bias towards certain features with larger scales and enhances the performance of unsupervised learning models by providing a level playing field for all variables. By standardising the data preprocessing stage, you can improve the accuracy and reliability of your unsupervised learning results.