
Unveiling the Intricacies of the Deep Boltzmann Machine: A Comprehensive Exploration
24 March 2024
Understanding Deep Boltzmann Machines
Introduction to Deep Boltzmann Machines
The realm of artificial intelligence (AI) continues to expand with innovative models that enhance machine learning capabilities. Among these models, the Deep Boltzmann Machine (DBM) stands out as a powerful generative model that can learn complex data distributions. DBMs are a sophisticated extension of the simpler Boltzmann Machine, designed to capture intricate structures within large datasets.
The Structure of a DBM
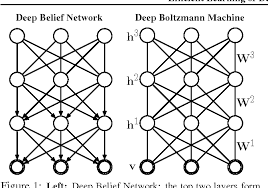
A DBM consists of multiple layers of stochastic, or random, hidden units between an input layer and an output layer. Unlike their predecessor, the Restricted Boltzmann Machine (RBM), which has only one hidden layer, DBMs have several hidden layers that allow for more levels of abstraction and representation of data.

The connections in a DBM are undirected and symmetric, which means that information is passed bi-directionally between units. These connections enable the model to establish deep representations and capture complex relationships within the data it is trained on.
Training Deep Boltzmann Machines
Training a DBM is computationally intensive due to its deep architecture. It involves adjusting the weights between units based on data inputs so that the model can learn to reconstruct its inputs accurately. The process uses an algorithm called Contrastive Divergence (CD), alongside other techniques like Persistent Contrastive Divergence (PCD) for more efficient training.
One key challenge in training DBMs is ensuring that each layer learns features without disrupting what has been learned by other layers. This requires careful tuning and potentially sophisticated training algorithms to achieve optimal performance.
Applications of Deep Boltzmann Machines
DBMs find applications across various domains where unsupervised learning is crucial. They are particularly useful for:
- Feature Learning: They can automatically discover representations needed for detection or classification tasks without human intervention.
- Dimensionality Reduction: Similar to principal component analysis (PCA), they can reduce the number of random variables under consideration.
- Classification: Once trained, they can classify new instances with high accuracy by comparing them against learned data distributions.
- Collaborative Filtering: In recommendation systems, they help predict user preferences based on underlying patterns in user-item interactions.
The Future of Deep Boltzmann Machines
The potential for further research into DBMs remains vast as we continue to explore their capabilities and improve upon their architecture and training methods. As computational power increases and new techniques emerge, we may see even more innovative applications for these versatile models in AI research and real-world applications.
In conclusion, while challenging in terms of computational resources required for training, the depth and flexibility offered by Deep Boltzmann Machines make them an invaluable tool in modern AI practices – pushing forward our understanding and application of machine learning technologies.
Exploring Deep Boltzmann Machines: An Insight into Their Mechanisms, Training Challenges, Applications, and Future Prospects
- What is a Deep Boltzmann Machine (DBM)?
- How does a Deep Boltzmann Machine differ from a Boltzmann Machine?
- What are the key components of a Deep Boltzmann Machine?
- How is training conducted for Deep Boltzmann Machines?
- What are the main challenges in training Deep Boltzmann Machines?
- In which domains or applications are Deep Boltzmann Machines commonly used?
- What is the future outlook for research and development involving Deep Boltzmann Machines?
What is a Deep Boltzmann Machine (DBM)?
A Deep Boltzmann Machine (DBM) is a sophisticated generative model in the realm of artificial intelligence that extends the capabilities of the traditional Boltzmann Machine. Comprising multiple layers of stochastic hidden units, a DBM is designed to learn complex data distributions by capturing intricate structures within large datasets. Unlike its predecessor, the Restricted Boltzmann Machine (RBM), which has a single hidden layer, DBMs leverage multiple hidden layers to enable deeper levels of abstraction and representation of data. This multi-layered architecture with undirected and symmetric connections allows the model to establish deep representations and capture intricate relationships within the data it is trained on.
How does a Deep Boltzmann Machine differ from a Boltzmann Machine?
A common query regarding Deep Boltzmann Machines often revolves around understanding their distinction from Boltzmann Machines. The key disparity lies in their architecture – while a Boltzmann Machine comprises a single layer of hidden units, a Deep Boltzmann Machine extends this structure by incorporating multiple layers of hidden units. This deeper architecture allows Deep Boltzmann Machines to capture more complex relationships within data through additional levels of abstraction. By leveraging these multiple layers, Deep Boltzmann Machines can learn intricate representations and patterns in datasets that may be challenging for traditional Boltzmann Machines to discern effectively.
What are the key components of a Deep Boltzmann Machine?
When exploring the key components of a Deep Boltzmann Machine (DBM), it is essential to understand its intricate structure. A DBM comprises multiple layers of stochastic hidden units, forming a deep neural network architecture. These hidden layers facilitate the model’s ability to learn complex data representations through unsupervised learning. The connections between units in a DBM are undirected and symmetric, allowing for bidirectional information flow and enabling the model to capture hierarchical features within the data. Training a DBM involves adjusting the weights between these layers using algorithms such as Contrastive Divergence, essential for enhancing the model’s capacity to reconstruct input data accurately. Overall, the layered design and interconnectedness of units are fundamental components that define the functionality and power of a Deep Boltzmann Machine in learning intricate data distributions.
How is training conducted for Deep Boltzmann Machines?
Training Deep Boltzmann Machines involves a complex process that requires careful consideration of the model’s deep architecture. The training of DBMs is computationally intensive and typically involves adjusting the weights between units based on input data to enable the model to reconstruct its inputs accurately. Contrastive Divergence (CD) is a commonly used algorithm for training DBMs, along with techniques like Persistent Contrastive Divergence (PCD) to enhance training efficiency. One of the key challenges in training DBMs is ensuring that each layer learns features without interfering with the information learned by other layers, necessitating meticulous tuning and potentially advanced training algorithms to achieve optimal performance.
What are the main challenges in training Deep Boltzmann Machines?
Training Deep Boltzmann Machines (DBMs) presents several significant challenges, primarily due to their complex and deep architecture. One of the foremost difficulties is the computational expense; the multiple layers of hidden units require a substantial amount of processing power for both forward and backward pass calculations during training. Furthermore, obtaining a good initialisation of weights that allows for efficient learning can be tricky, as poor initialisation may lead to slow convergence or getting stuck in poor local optima. Another challenge is the precise tuning of hyperparameters, such as learning rates and regularisation terms, which is crucial for the model’s performance but often involves a time-consuming process of trial and error. Additionally, ensuring that each layer learns useful representations without interfering with other layers’ features requires sophisticated training strategies that can effectively balance learning across the DBM’s depth. These challenges make training DBMs an intricate task that researchers continue to address through advanced algorithms and optimisation techniques.
In which domains or applications are Deep Boltzmann Machines commonly used?
Deep Boltzmann Machines (DBMs) are commonly used in various domains and applications where unsupervised learning plays a vital role. These sophisticated generative models find significant utility in feature learning, where they autonomously discover essential representations necessary for tasks like detection or classification without human intervention. Additionally, DBMs are employed in dimensionality reduction tasks akin to principal component analysis (PCA), helping to streamline the consideration of random variables. In classification scenarios, once trained, DBMs can accurately classify new instances by comparing them against learned data distributions. Furthermore, in collaborative filtering applications such as recommendation systems, DBMs excel at predicting user preferences based on underlying patterns in user-item interactions.
What is the future outlook for research and development involving Deep Boltzmann Machines?
The future outlook for research and development involving Deep Boltzmann Machines (DBMs) is one of cautious optimism, as the field recognises both the model’s potential and its current limitations. As computational methods advance, there is an expectation that more efficient training algorithms will be developed to mitigate the computational intensity of DBMs. This could lead to a resurgence in their popularity, particularly in unsupervised learning tasks where their capacity for feature learning and dimensionality reduction shines. Moreover, with ongoing interest in deep learning architectures, DBMs may find innovative applications in areas such as bioinformatics, complex system modelling, and integrative data analysis. Researchers are also exploring hybrid models that combine the strengths of DBMs with other neural network architectures to overcome existing challenges. As such, while DBMs may not currently be at the forefront of AI research, they remain a compelling area of study with the potential for significant contributions to the field as understanding and technology evolve.