
Unveiling the Power of LeNet in Deep Learning: A Journey into Convolutional Neural Networks
04 February 2025
Exploring LeNet Deep Learning
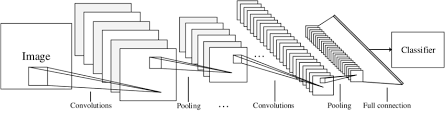
LeNet is a pioneering convolutional neural network (CNN) architecture that laid the foundation for modern deep learning. Developed by Yann LeCun and his team in the 1990s, LeNet was designed to recognize handwritten digits in images, making it a breakthrough in the field of computer vision.
The architecture of LeNet consists of several layers, including convolutional layers, pooling layers, and fully connected layers. These layers work together to extract features from input data and make predictions based on these features.
One of the key innovations of LeNet is the use of convolutional layers, which apply filters to input data to detect patterns and features. This approach allows the network to learn hierarchical representations of the input data, making it highly effective for tasks such as image recognition.
LeNet has been widely used in various applications, including optical character recognition (OCR), object detection, and facial recognition. Its success has paved the way for more advanced CNN architectures, such as AlexNet, VGGNet, and ResNet.
In conclusion, LeNet deep learning has revolutionized the field of computer vision and set the stage for modern deep learning techniques. Its impact can be seen in a wide range of applications that rely on image analysis and pattern recognition. As technology continues to evolve, LeNet’s legacy remains strong as a foundational model for understanding and implementing deep learning algorithms.
8 Essential Tips for Enhancing Handwritten Digit Recognition with LeNet Deep Learning
- Use LeNet-5 architecture for handwritten digit recognition tasks.
- Preprocess input images by normalizing pixel values to the range of 0 to 1.
- Apply techniques like data augmentation to increase the size of the training dataset.
- Utilize ReLU activation function in hidden layers for better convergence.
- Experiment with different optimizers such as SGD, Adam, or RMSprop for training.
- Monitor training progress using metrics like accuracy and loss on validation data.
- Regularize the model using techniques like dropout to prevent overfitting.
- Fine-tune hyperparameters such as learning rate and batch size for optimal performance.
Use LeNet-5 architecture for handwritten digit recognition tasks.
When tackling handwritten digit recognition tasks, leveraging the LeNet-5 architecture can be highly beneficial. Developed by Yann LeCun and his team, LeNet-5 is specifically designed to excel in recognising handwritten digits in images. Its convolutional layers, pooling layers, and fully connected layers work harmoniously to extract intricate features from the input data, making it a powerful tool for such tasks. By utilising the LeNet-5 architecture, researchers and practitioners can enhance the accuracy and efficiency of their handwritten digit recognition models, ultimately achieving superior results in this domain.
Preprocess input images by normalizing pixel values to the range of 0 to 1.
When working with LeNet deep learning, a crucial tip is to preprocess input images by normalizing pixel values to the range of 0 to 1. This preprocessing step is essential as it helps in standardizing the input data, making it easier for the neural network to learn and make accurate predictions. By scaling pixel values to a consistent range, the model can effectively identify patterns and features in the images, leading to improved performance and generalization.
Apply techniques like data augmentation to increase the size of the training dataset.
To enhance the performance of LeNet deep learning models, it is advisable to implement strategies such as data augmentation to expand the training dataset. By applying techniques like rotation, flipping, scaling, and adding noise to the existing data, we can generate additional diverse examples for the model to learn from. This helps improve the model’s ability to generalize and make accurate predictions on unseen data by exposing it to a wider range of variations and scenarios during training. Data augmentation plays a crucial role in boosting the robustness and effectiveness of LeNet networks in handling real-world tasks with greater accuracy and reliability.
Utilize ReLU activation function in hidden layers for better convergence.
When implementing LeNet deep learning, it is advisable to utilise the Rectified Linear Unit (ReLU) activation function in the hidden layers for improved convergence. ReLU helps address the vanishing gradient problem and accelerates training by allowing the network to learn faster and more effectively. By using ReLU in hidden layers, the model can achieve better convergence, leading to enhanced performance and more accurate predictions.
Experiment with different optimizers such as SGD, Adam, or RMSprop for training.
To enhance the training process of LeNet deep learning model, it is recommended to experiment with various optimizers like Stochastic Gradient Descent (SGD), Adam, or RMSprop. Each optimizer comes with its unique characteristics and can have a significant impact on the model’s performance. By testing different optimizers, researchers and practitioners can fine-tune the training process to achieve better convergence rates, improved accuracy, and faster training times. This experimentation allows for a deeper understanding of how different optimizers interact with the model architecture, leading to more effective and efficient training of the LeNet deep learning model.
Monitor training progress using metrics like accuracy and loss on validation data.
Monitoring the training progress of a LeNet deep learning model is crucial for assessing its performance and ensuring optimal results. By tracking metrics such as accuracy and loss on validation data throughout the training process, developers can gain valuable insights into how well the model is learning and generalizing from the data. High accuracy and low loss values indicate that the model is performing well, while fluctuations or stagnation in these metrics may signal issues that need to be addressed, such as overfitting or underfitting. Continuous monitoring of these metrics allows for timely adjustments to the model’s architecture or training parameters, leading to improved performance and better outcomes in real-world applications.
Regularize the model using techniques like dropout to prevent overfitting.
Regularizing the LeNet deep learning model using techniques like dropout is crucial to prevent overfitting. Dropout involves randomly deactivating a certain percentage of neurons during training, forcing the network to learn more robust and generalizable features. By implementing dropout, the model becomes less likely to memorize the training data and more capable of generalizing well to unseen data. This regularization technique helps improve the model’s performance and ensures that it can effectively handle new inputs without overfitting to the training set.
Fine-tune hyperparameters such as learning rate and batch size for optimal performance.
To achieve optimal performance in LeNet deep learning, it is crucial to fine-tune hyperparameters such as the learning rate and batch size. The learning rate determines how quickly the model adapts to the training data, while the batch size affects the efficiency of parameter updates during training. By experimenting with different values for these hyperparameters and finding the right balance, researchers and practitioners can enhance the accuracy and efficiency of their LeNet models, ultimately improving their overall performance in various computer vision tasks.