
Unlocking the Power of Neural Networks with Scikit-learn
26 June 2024
Exploring Neural Network with Scikit-learn
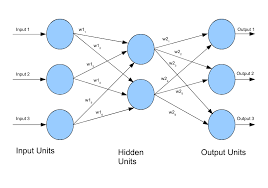
Neural networks are a powerful tool in the field of artificial intelligence and machine learning. They are capable of learning complex patterns in data and making accurate predictions. When combined with the popular Python library Scikit-learn, building and training neural networks becomes more accessible to developers and data scientists.
Scikit-learn is a versatile machine learning library that provides various tools for data preprocessing, model selection, and evaluation. It also includes a user-friendly interface for building neural network models using the MLPClassifier and MLPRegressor classes.
To create a neural network model with Scikit-learn, you first need to define the architecture of the network, including the number of layers, neurons in each layer, activation functions, and other hyperparameters. Then, you can fit the model to your training data using the fit() method.
Once the model is trained, you can make predictions on new data using the predict() method. Scikit-learn also provides tools for evaluating the performance of your neural network model, such as accuracy score, confusion matrix, and classification report.
In conclusion, combining neural networks with Scikit-learn opens up a world of possibilities for building sophisticated machine learning models. Whether you are a beginner or an experienced data scientist, exploring neural networks with Scikit-learn can help you unlock new insights from your data and make more accurate predictions.
8 Essential Tips for Optimising Neural Network Performance with Scikit-Learn
- Use appropriate activation functions such as ‘relu’ or ‘sigmoid’.
- Normalize input data to improve convergence speed and performance.
- Choose the number of hidden layers and neurons carefully to avoid overfitting or underfitting.
- Experiment with different optimizers like ‘adam’ or ‘sgd’ to find the best one for your model.
- Monitor training progress using validation data and adjust hyperparameters accordingly.
- Implement early stopping to prevent overfitting by monitoring validation loss during training.
- Regularize your model using techniques like L1 or L2 regularization to prevent overfitting.
- Visualize neural network architecture using tools like TensorBoard for better understanding.
Use appropriate activation functions such as ‘relu’ or ‘sigmoid’.
When working with neural networks in Scikit-learn, it is essential to choose appropriate activation functions for optimal model performance. Activation functions like ‘relu’ or ‘sigmoid’ play a crucial role in shaping the non-linear relationships within the network and influencing the model’s ability to learn complex patterns in the data. By selecting the right activation functions, such as ‘relu’ for hidden layers and ‘sigmoid’ for output layers in classification tasks, you can enhance the network’s learning capabilities and improve its predictive accuracy. Carefully considering and implementing suitable activation functions is key to unlocking the full potential of neural networks built with Scikit-learn.
Normalize input data to improve convergence speed and performance.
Normalizing input data is a crucial tip when working with neural networks in Scikit-learn. By scaling the input data to a similar range, we can improve the convergence speed and overall performance of the neural network model. Normalization helps prevent certain features from dominating the learning process due to their larger scales, ensuring that each feature contributes proportionally to the model’s training. This simple yet effective practice can lead to more stable training, faster convergence, and ultimately better predictive accuracy in neural network models built using Scikit-learn.
Choose the number of hidden layers and neurons carefully to avoid overfitting or underfitting.
When working with neural networks in Scikit-learn, it is crucial to carefully select the number of hidden layers and neurons to prevent overfitting or underfitting of the model. Overfitting occurs when the model is too complex and learns noise in the training data, leading to poor generalization on unseen data. On the other hand, underfitting happens when the model is too simple to capture the underlying patterns in the data, resulting in low accuracy. By striking a balance and tuning the architecture of the neural network appropriately, you can enhance its performance and ensure optimal predictive capabilities.
Experiment with different optimizers like ‘adam’ or ‘sgd’ to find the best one for your model.
When working with neural networks in Scikit-learn, it is advisable to experiment with different optimizers such as ‘adam’ or ‘sgd’ to determine the most suitable one for your model. Optimizers play a crucial role in training neural networks by adjusting the weights and biases to minimise the loss function. By trying out various optimizers, you can fine-tune the performance of your model and potentially improve its accuracy and convergence speed. It is essential to explore different optimizers to find the one that best suits your specific dataset and problem domain, ultimately enhancing the effectiveness of your neural network model.
Monitor training progress using validation data and adjust hyperparameters accordingly.
Monitoring the training progress of a neural network model using validation data is crucial for achieving optimal performance. By observing how the model performs on data that it has not been trained on, we can identify overfitting or underfitting issues and make informed decisions about adjusting hyperparameters. Regularly evaluating the model’s performance on validation data allows us to fine-tune the neural network’s architecture and hyperparameters to improve its generalization capabilities and ensure that it can effectively handle unseen data. This iterative process of monitoring, adjusting, and validating helps in creating a well-performing neural network model using Scikit-learn.
Implement early stopping to prevent overfitting by monitoring validation loss during training.
Implementing early stopping is a valuable tip when using neural networks with Scikit-learn. By monitoring the validation loss during training, you can prevent overfitting and ensure that your model generalises well to unseen data. Early stopping allows you to halt the training process once the validation loss starts to increase, indicating that the model is starting to overfit the training data. This technique helps in creating more robust and accurate neural network models by finding the optimal balance between training performance and generalisation ability.
Regularize your model using techniques like L1 or L2 regularization to prevent overfitting.
Regularizing your neural network model using techniques like L1 or L2 regularization is essential to prevent overfitting. Overfitting occurs when the model learns the noise in the training data rather than the underlying patterns, leading to poor generalization on unseen data. By incorporating regularization methods such as L1 (Lasso) or L2 (Ridge) into your neural network with Scikit-learn, you can impose constraints on the model’s weights and reduce its complexity, ultimately improving its performance on new data.
Visualize neural network architecture using tools like TensorBoard for better understanding.
Visualizing the architecture of a neural network using tools like TensorBoard can greatly enhance understanding and insight into the model’s inner workings. By visualizing the structure of the network, including its layers, connections, and activations, developers and data scientists can gain valuable insights into how information flows through the model. This visual representation not only aids in debugging and troubleshooting potential issues but also provides a clearer picture of how the neural network processes data, leading to more informed decisions when refining and improving the model.