
Unleashing the Power of Neural Networks: Revolutionizing Artificial Intelligence
23 September 2023
Neural networks are a type of artificial intelligence (AI) that are inspired by the way biological neurons work in the brain. Neural networks are a set of algorithms, modeled loosely after the human brain, that are designed to recognize patterns. They interpret sensory data through a kind of machine perception, labeling or clustering raw input. The patterns they recognize are numerical, contained in vectors, into which all real-world data, be it images, sound, text or time series, must be translated.
Neural networks have been around since the 1940s but have only recently become popular due to advances in computing power and algorithms. They can be used for a variety of tasks such as image recognition and classification, natural language processing (NLP), recommendation systems and even autonomous vehicles.
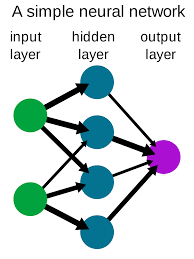
The way neural networks work is by connecting several nodes together in layers. Each node is connected to other nodes in the layer before it and after it. Each connection has an associated weight which is adjusted during training so that the network can learn to recognize patterns in its inputs and produce an output accordingly. The process of learning involves adjusting these weights so that the network can accurately predict what it sees as input and produce an output accordingly.
The most popular type of neural network is called a deep neural network (DNN). This type of neural network consists of multiple layers with each layer containing many neurons which are connected to each other in various ways. A DNN can learn complex functions by using backpropagation which involves adjusting the weights between neurons based on how accurate its predictions were compared to what was expected as input.
Neural networks have become increasingly popular due to their ability to solve complex problems with relative ease compared to traditional methods such as linear regression or logistic regression. They can also learn from data without being explicitly programmed with rules or algorithms which makes them more suitable for solving complex tasks like image recognition or natural language processing where there may not be any clear rules or algorithms available for programming a computer to solve the task at hand efficiently.
In conclusion, neural networks offer an exciting new way for machines to learn from data without being explicitly programmed with rules or algorithms and have become increasingly popular due to their ability to solve complex problems with relative ease compared to traditional methods such as linear regression or logistic regression.
Essential Tips for Neural Network Success: A Guide to Getting Started and Optimizing Performance
- Start by familiarising yourself with the basic concepts of neural networks, such as neurons, weights, activation functions and backpropagation.
- Experiment with different architectures to find the best network for your problem.
- Use regularisation techniques like dropout and early stopping to prevent overfitting in your model.
- Take advantage of training accelerators such as GPUs or TPUs to speed up training times and increase accuracy.
- Utilise open source libraries like Keras or TensorFlow to quickly prototype and deploy neural networks without having to write complex code from scratch.
Start by familiarising yourself with the basic concepts of neural networks, such as neurons, weights, activation functions and backpropagation.
Neural networks are an exciting area of research and development that can be used to solve a variety of problems. However, it is important to understand the basic concepts before diving into more complex topics.
Neurons are the building blocks of neural networks, and they are responsible for processing information. Weights are assigned to neurons which determine how strong the connection between neurons is. Activation functions determine how neurons respond to inputs, and backpropagation is the process of adjusting weights in order to optimize the network’s performance.
By familiarising yourself with these concepts, you will have a better understanding of how neural networks work and be able to use them more effectively. Additionally, understanding these concepts will help you develop your own neural networks or modify existing ones.
Overall, it is important to take some time to understand the basics of neural networks before attempting more complicated tasks. Doing so will give you a better foundation for further exploration and allow you to make better use of this powerful technology.
Experiment with different architectures to find the best network for your problem.
When it comes to building neural networks, one valuable tip is to experiment with different architectures in order to find the best network for your specific problem. Neural networks are highly flexible and can be customized to suit different types of tasks. By exploring various architectures, you can optimize the performance and efficiency of your network.
The architecture of a neural network refers to its structure, including the number of layers, the number of nodes in each layer, and how these layers are interconnected. Different architectures may have varying strengths and weaknesses depending on the nature of your problem.
Experimenting with different architectures allows you to fine-tune your network’s capabilities. For example, if you’re working on an image recognition task, you might try using convolutional neural networks (CNNs) which are specifically designed for analyzing visual data. On the other hand, if you’re dealing with sequential data like natural language processing, recurrent neural networks (RNNs) or long short-term memory (LSTM) networks might be more suitable.
By testing different architectures, you can assess their performance metrics such as accuracy, precision, recall, or computational efficiency. This iterative process helps you identify which architecture works best for your specific problem domain.
Furthermore, experimenting with architectures allows you to gain insights into how different components affect network performance. You can explore the impact of changing activation functions, adjusting layer sizes, or incorporating regularization techniques such as dropout or batch normalization.
It’s important to note that finding the optimal architecture often requires a balance between complexity and simplicity. While a larger network with more layers may capture intricate patterns better, it could also lead to overfitting if not properly regularized. Conversely, a smaller network may not have enough capacity to capture complex relationships within the data.
In conclusion, when working with neural networks, don’t hesitate to experiment with different architectures tailored to your specific problem. The process of exploring various configurations will allow you to fine-tune your network’s performance, optimize its capabilities, and ultimately achieve better results.
Use regularisation techniques like dropout and early stopping to prevent overfitting in your model.
When building neural networks, one common challenge that arises is overfitting. Overfitting occurs when a model becomes too complex and starts to memorize the training data instead of learning the underlying patterns. This can lead to poor generalization and decreased performance on unseen data. Fortunately, there are techniques like dropout and early stopping that can help prevent overfitting and improve the overall performance of your model.
Dropout is a regularization technique that randomly drops out a certain percentage of neurons during training. By doing so, it forces the network to learn more robust and generalizable features. Dropout prevents neurons from relying too heavily on specific inputs or co-adapting with other neurons, thus reducing overfitting. It acts as a form of ensemble learning by training different subnetworks within the main network, which helps in creating a more robust model.
Early stopping is another effective technique for preventing overfitting. It involves monitoring the performance of the model during training on both the training set and a separate validation set. As training progresses, if the performance on the validation set starts to deteriorate while the performance on the training set continues to improve, it indicates that the model has started to overfit. Early stopping allows you to stop training at an optimal point before overfitting occurs, thereby preventing unnecessary iterations that may harm generalization.
By incorporating dropout and early stopping techniques into your neural network architecture, you can significantly reduce overfitting and improve its ability to generalize well on unseen data. These techniques help strike a balance between capturing important patterns in the data and avoiding excessive complexity that hampers performance.
In conclusion, regularisation techniques like dropout and early stopping are valuable tools when working with neural networks. They play a crucial role in preventing overfitting by promoting robustness and generalization in your models. By employing these techniques wisely, you can enhance your neural network’s performance and ensure its effectiveness in real-world scenarios where unseen data is encountered.
Take advantage of training accelerators such as GPUs or TPUs to speed up training times and increase accuracy.
When it comes to training neural networks, time and accuracy are two crucial factors. Fortunately, there is a powerful tip that can significantly enhance both aspects: taking advantage of training accelerators such as GPUs (Graphics Processing Units) or TPUs (Tensor Processing Units).
Training a neural network involves performing numerous complex calculations and operations. This process can be computationally intensive and time-consuming when using traditional CPUs (Central Processing Units). However, GPUs and TPUs are specifically designed to handle parallel processing tasks efficiently, making them ideal for accelerating the training process.
By utilizing GPUs or TPUs, you can experience remarkable improvements in training times. These accelerators can distribute the computational workload across multiple cores simultaneously, enabling faster execution of the neural network’s calculations. As a result, what might have taken days or weeks to train on a CPU can now be accomplished in a fraction of the time.
Not only do these accelerators expedite training times, but they also contribute to increased accuracy. Neural networks often require large amounts of data for training purposes. GPUs and TPUs allow for larger batch sizes, meaning more data can be processed simultaneously during each iteration. This expanded capacity enables better generalization and improved accuracy in the final model.
It’s worth noting that not all neural network frameworks support GPUs or TPUs out of the box. However, many popular frameworks like TensorFlow and PyTorch have integrated support for these accelerators, making it easier than ever to harness their power.
In conclusion, incorporating training accelerators such as GPUs or TPUs into your neural network workflow can yield significant benefits in terms of both speed and accuracy. By leveraging their parallel processing capabilities, you can reduce training times from weeks to hours or even minutes while achieving higher levels of accuracy in your models. So why not embrace this tip and unlock the true potential of your neural networks?
Utilise open source libraries like Keras or TensorFlow to quickly prototype and deploy neural networks without having to write complex code from scratch.
When it comes to developing neural networks, utilizing open source libraries like Keras or TensorFlow can be a game-changer. These libraries provide a wealth of pre-built functions and tools that allow developers to quickly prototype and deploy neural networks without the need to write complex code from scratch.
One of the major advantages of using open source libraries is the time and effort saved in implementing neural networks. Instead of spending hours or even days coding every aspect of a neural network, developers can leverage the functionalities offered by these libraries. Keras, for example, provides a high-level API that simplifies the process of building and training neural networks. TensorFlow, on the other hand, offers a more flexible and comprehensive framework for developing machine learning models.
By using these libraries, developers can focus their energy on designing and fine-tuning their neural network architectures rather than getting caught up in low-level implementation details. With pre-built modules for layers, activation functions, optimizers, and more, building complex neural networks becomes much more accessible.
Furthermore, open source libraries like Keras and TensorFlow have large communities surrounding them. This means that developers can benefit from an extensive pool of resources such as documentation, tutorials, and forums where they can seek help or share their knowledge with others. This kind of collaborative environment encourages learning and innovation within the field of neural networks.
Another significant advantage is that these libraries are constantly evolving with new updates and improvements being released regularly. This ensures that developers have access to state-of-the-art techniques and algorithms without having to reinvent the wheel themselves.
In conclusion, utilizing open source libraries like Keras or TensorFlow is a valuable tip when working with neural networks. They provide ready-to-use tools and functionalities that streamline the development process while also fostering collaboration within the developer community. By leveraging these powerful resources, developers can prototype and deploy neural networks efficiently without having to write complex code from scratch.